...
| Warning | ||
|---|---|---|
| ||
Materials from External Review work at Dagstuhl Sprint |
| Expand | ||
|---|---|---|
| ||
Virtual MRT meeting 2019-01-30Agenda (as in invite of 2019-01-28)Goal: To have a draft program of work for NADDI Sprint (to submit to EB), and an initial list of proposed tasks.
Suggestions: - Documentation of datum-based model application to examples of event data, aggregates, etc.
- Existing modeling technical requirements/issues
- Others
- Are there ideas/candidate tools which need to be written up/further explored?
- Identify tester and potential testers (We may not get this far, but if we have time it would be good) Minutes DDI4 MRT Virtual meeting 2019-01-30Attendees: Achim, Arofan, Dan G., Flavio, Hilde, Jay, Larry, Oliver, Wendy Apologies: Jon 1. Description of what is needed for organizing NADDI Sprint (from Achim):A goal for the meeting is to have an agreed document regarding the NADDI Sprint planning ready to send to the AG to inform their discussions at their next meeting, and further to apply for funding of the possible sprint. Achim prepared and sent out the document ‘NADDISprintPlanning.docx’ to the srg list in advance of the meeting. This is a shell document where some content of the document needed to be filled in or reviewed and agreed while the meeting. The meeting was structured in three parts: 1) Topics for the possible NADDI Sprint; 2) Review of possible participants and funding; 3) Other organizational issues regarding the possible NADDI Sprint. 1) Topics for the possible NADDI Sprint (see point 2 in the agenda)a) Documentation of datum-based model application to examples of data structures (to be discussed and agreed at the meeting which data structures to focus on at the Sprint). b) Discussion and possible resolution of structural model issues:
Status: Points a) and b) agreed as topics for the possible NADDI Sprint. Discussion and agreements regarding example data structures a) Example data structures (point a) were discussed after the structural model issues (point b). The discussion regarding which data structures to focus on as examples at the possible NADDI Sprint was centered on whether to focus on common vs. complex cases and corner cases. Dan G. pointed out the importance of modelling complex cases, as more common or simple cases would then be solved at the same time. Others pointed out that issues could occur even if a similar approach is used. Agreement was reached to focus on the common cases as a preparation for the possible NADDI Sprint. Status: Agreement was reached to focus on the following common data structures for the possible NADDI Sprint:
Arofan and Wendy pointed out that the Variable Cascade documentation (provided for example in the Variable Cascade presentation from the Dagstuhl workshop DDI Train-the-Trainers 2018) indicates the style and level of information needed for documentation. Status: Wendy will add this as a prototype review comment. After NADDI further data structures may possibly be explored, for example NoSQL (non SQL) data like Hadoop data, graphs etc. Status: Agreed In the Appendix an example from the discussion provided by Larry is found. Discussion and agreements regarding structural model issues b) Structural model issues (point b) were discussed before the example data structures (point a). Conceptual resolution/MRT: Jay brought up the issue if structural issues could be resolved conceptually or by using the MRT approach. Flavio pointed out the need to look at many different examples to check out structural modelling issues. Achim indicated this could be a topic for the possible face to face meeting and something for a work group to focus on in advance. Complexity of the model: Flavio commented that the model is complex because it is made complex. It has multiple levels and covers both common and domain specific needs. To simplify the understanding, some of the content could for example be hidden for specific user groups. Achim asks if the model can be improved by focusing on questions like:
Work regarding the complexity of the model could be done in advance and brought to the sprint. Review of views: The revision of Views is important. Achim points out that even a simple view like the Agency view drives in a lot of classes. Flavio points out that Views are complex because they currently are designed to cover multiple dimensions. The Classification View is for example meant to cover reuse, classification management and publishing. This and other views would need separation into smaller sets to be easier to understand. Larry expresses that the model currently is highly connected but that good documentation can help the understanding. Status: Agreement to focus on the four bullet points under b) above for the planned Sprint. Tasks should be broken up as much as possible. Smaller groups could work on each of those and get back with a proposal for the full group after a week or two. A specific person should be responsible to follow up on the work on each task. 2) Review of list of possible participants and fundingThe following agreement was made: The following people would be available in person for this meeting (their need for funding in parenthesis):
Most of the people would need funding from the DDI Alliance as specified in the NADDISprintPlanning_1_0.docx document. Oliver Hopt would be available by phone. 3) Other organizational issues regarding the possible NADDI SprintPossibilities for meeting location and lodging have been checked out and booked by Flavio and Achim as follows:
Two documents are sent to the AG for their feedback prior to their next meeting (also sent to the srg list):
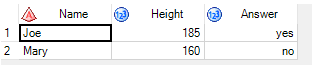
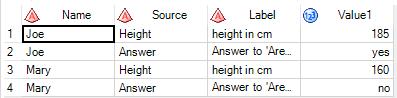
Further follow-up is required regarding organizing the start-up of the work, and making plans for what needs to be prepared in advance of the possible NADDI Sprint. AppendixExample from Larry related to discussions of point a): With the ability to describe data at the datum level DDI should be able to describe data like that in the following example through transformations from traditional rectangular (wide) layouts into key-value (tall) representations. DDI4 can currently describe the data in the wide layout, but, though we have discussed how to do the tall representation, that work has not been completed in the model. Wide data table: Corresponding tall representation: Transformations between these layouts are common in data software packages. The SAS code below shows the transformation from the wide to the tall. Note that in the Tall representation the column Source is a pointer to a variable in the wide layout. The column Value1 is not a traditional variable, in that there is no one value domain or concept associated with the whole column, instead those things depend on the pointer in Source. If we can properly describe datum level metadata we should be able to describe the value domain and concept associated with the “yes” category label (which is actually a code of 1 in the SAS dataset) in the Value1 column. We should also be able to describe the meaning and units of measurement of the value 185 in the same column. Proc format; value yn 1="yes" 2="no" ; /* example rectangular file */ data fooWide; input Name $ Height Answer; label Name="Person name" Height="height in cm" Answer="Answer to 'Are you hapy?"; format Answer yn.; datalines; Joe 185 1 Mary 160 2 ; run; proc sort data=work.fooRect; by Name; PROC TRANSPOSE DATA=fooWide OUT=WORK.fooTall(LABEL="Transposed WORK.FOORECT") PREFIX=Value NAME=Source LABEL=Label ; BY Name; VAR Height Answer; format Value1 yn |
| Expand | ||
|---|---|---|
| ||
DDI4 MRT Virtual meeting 2019-01-23Agenda (as in invite of 2019-01-23)Goal: This meeting should get us to the point where we are ready to propose a formalization of this effort to the DDI Executive (or take other steps necessary for approval). To that end, the following agenda is proposed: Agreeing the document as regards: - Organization - Scope - Timeline Details on organization and scope: - MRT Lifecycle feedback loop - Status of the sub-groups (see new version of document, section on organisation and structure, as well as section 4 in the minutes of last meeting). - Alignment of other standards, provenance (see new version of document, section on alignment with metadata structures in DDI4 Core, and discussions in the Appendix of the minutes of last meeting) - Finalizing the document and process for approval: Things to be added, changed or removed – or approve new version as is? Minutes DDI4 MRT Virtual meeting 2019-01-23Attendees: Achim, Arofan, Hilde, Jay, Jon, Larry, Oliver, Wendy Organization and scope:Basis for the discussion: Document updated by Arofan with input from Achim, ‘MRT_DDI4Core_Diff_0_2_and_0_3_JW’, attachment to email from Achim to srg list 2019-01-23. The goal of the meeting was to finalize the MRT-DDI4 Core document to be sent to the Advisory Group for their comments. Jay suggested to start to plan work tasks as well at this meeting. Status: Agreement to take on tasks later on, and to prioritize the finalization of the document at this meeting. Discussions regarding the document:-Organisation and Structure: Achim points out the Core group guides the whole effort, defines sub-tasks and assigns a responsible person for the task who reports back to the full group. The feedback loops should be done in short, iterative cycles. Tasks are not long term, and should be discrete and well-defined. Important that the document reflects this. Status: Agreed -Role of the MRT in the organization: Wendy asks how the MRT relates to other DDI groups. Larry points out that this is a new way of organizing the work of the Modelling Team. Status: Agreement that MRT replaces the Modelling Team. The work of the group should be well aligned with the Advisory Group. -MRT feedback loop: The requirements for the feedback loop were discussed. Achim points out that the requirements are just a repetition of earlier goals of the Moving Forward project. Proposals for amendments to bullet points (for clarification purposes): -Remove ‘if required’ from the ‘looseless roundtrip’ bullet point. -Add ‘Stability’ to the ‘Consistency’ bullet point. -‘Persistence of the model’ change to ‘Persistent expression of the model in canonical form’ (not to be confused with canonical XMI). Status: Agreement to update the bullet points accordingly. -Mapping of DDI4 to earlier versions of DDI: This was discussed at our last meeting (January 16th). Larry points out that conformance and divergence with previous versions of DDI should be clearly defined. Status: Agreed to include a section on this in the document. -Alignment with other metadata standards: Jay asks if SDMX should be mentioned in the list of standards included in the document. Arofan points out that the document indicates ‘at least’ which standards the DDI4 Core should be interoperable with. Status: Agreed to highlight ‘at least’ in the document. -Production process: Jon asks if the production process should be mentioned in the document. Arofan points out that this is a big and important topic that needs to be addressed. We will need to come back to what the options are. Status: Agreement that the production process should be identified in the document as something that would need to be addressed. Timeline:-Timing of the DDI4 Core work. Status: Agreement for the DDI Core work to take place in rapid cycles of weeks, not months. A calendar year is the anticipated goal. Leave wording in the document as stands. -Timing of the finalization of the document: Wendy, Achim and Arofan points out the importance of finalizing the document before the next meeting of the Advisory Group (scheduled to next Wednesday). Status: Agreed to finalise the document for Monday and send to the AG for their comments. Arofan send to the MRT group today (on the 23rd ) for comments. Other:NADDI Sprint: Achim proposes a face-to-face meeting with the group after NADDI, of possibly three days, and asked if people in the group would be interested in this. All participants on the call indicated that they would be interested. Their possibilities for attendance and dependencies are specified below:
Possible topic for the agenda of the NADDI Sprint: Flavio proposes to focus on the modelling requirements. Status: Agreement that Achim follows up regarding the possible NADDI Sprint with the AG, contact the local organisers regarding possible localities etc. |
| Expand | ||
|---|---|---|
| ||
Agenda (as in meeting notes from of 2019-01-09)Organizational approach of where we are going and how we organize the approach Modeling technical requirements - need to provide a summary for comprehension SPARKX cloud modeling approach for UML modeling https://www.sparxsystems.com.au/enterprise-architect/cloud-services/cloud-services.html Minutes DDI4 MRT Virtual meeting 2019-01-16Attendees:Achim, Arofan, Dan G., Flavio, Hilde, Jay, Larry, Oliver, Wendy Topics:At the meeting the organizational approach was discussed as described below. UML modelling tools was discussed by email between the last meeting and this meeting by Flavio and Achim (see information under 8) below as well as the full correspondence in the appendix). Provenance issues and relationship with other models were also discussed between the meetings by Flavio and Jay (also under 8) below and included in the appendix). Organizational approach:Basis for the discussion: A) Document ‘MRT_DDI4Core_0_2’, attachment in email from Arofan to srg list 2019-09-01. B) Achims questions to be clarified in order to build a good basis for the work next year, in email from Achim to srg list 2018-12-12. Achims questions (1 – 8) and their workflow status are specified below:
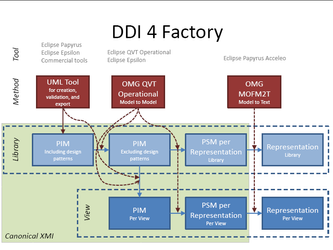
Status: Agreed 2. Focus on DDI 4 Core, like Conceptual, Data Description, and Process. These areas are important for any use case perspective. Additional areas can be identified according to business requirements. But the focus on a core increases the chances to have a robust and mature deliverable. Status: Agreed to focus on the core 3. Description of major tasks regarding major modeling issues -Provenance was brought in as a new topic in a discussion between last week’smeeting and this meeting, see point 8) and the appendix. Status: Needs follow-up discussions 4. Participants and their roles/perspectives -Proposal in the ‘MRT_DDI4Core_0_2’ document to have an administration group (coordination team) with sub-groups. Achim suggests that smaller groups can work independently on different things and get back to bigger groups with recommendations. Status: Agreed -Participants of the MRT coordination team: Arofan suggests that this group is the MRT group coordinating team, together with Jon who has also expressed interest in this. Status: Agreed -Sub-teams: In the ‘MRT_DDI4Core_0_2’ document, three possible sub-teams are proposed, all with an identified lead: a modelling sub-team, a representation sub-team (with sub-teams for each representation, xml, RDF, Phyton etc.), a documentation sub-team and a testing and representation sub-team. Larry expresses a concern for the idea of fixed sub-groups due as there may not be enough people for this. Achim proposes to think in terms of more ad hoc task oriented sub groups. Invite external experts when needed. Status: Needs follow-up work -Perspectives: A task proposed by Larry that also regards modeling (question 3 above) is to have DDI2 mapped into the DDI4 Core for the end of the year. Comment from Achim: This work can identify missing pieces and flaws in the modelling. Not sure if all can be resolved by the year, but should be possible to identify them. Do mapping first and then modelling. Comment from Arofan: Transformations should be developed. Flavio: A modelling tool should be used rather than excel for the mapping. Status: Agreement about the requirement about the mapping of DDI2 to DDI4. Needs follow-up work. Task proposed by Achim: Work on data description usage for different representations and data forms, for example unit record data, event long/short, aggregate/cube, single datum in a lake. Detailed tasks should be developed. Example data that can be used for this purpose are data from the Australian Election Study (Larry) and the ESS (Achim), the Alpha Network (Jay), possibly others. The Alpha Network has lots of different data types. Several of the relevant data sets are structured in DDI2. Where real data are difficult to provide or new, like a datum in a lake, made up examples should be provided. Status: Agreement on the task. Needs detailing of sub-tasks , follow-up work, who’s involved etc.. Tools: Flavio: Need to decide which tools to use in our work (see also discussions under 8) and discussion emails in the appendix). Status: Needs follow-up -Administrative work: Hilde does the meeting minutes Status: Agreed Further administrative work, chairing etc. Status: Needs follow up. 5. Is the proposed timeline for a DDI 4 Core at end of 2019 reasonable? Status: Agreed working goal. 6. The development of the business requirements document can be worked on in parallel but is not task of this group. Comment from Arofan: Some requirements identified by this work that affect the core areas could be interpreted as technical requirements and fed back to the MRT group and be a task for the modelers. Comment from Achim: The focus of the MRT approach is the goal of a stable DDI4 core in one year. The focus on business requirements should not be tied to close to the task in order not to delay this process. It would be important to distinguish between what we need to have in to have a functional DDI4 core, and what can be added later. Comment from Flavio: Agrees with Achim. For each step in the MRT cycle it should be decided what it would make sense to include. The MRT Coordination group should decide on this. Status: Achims proposal agreed. 7. Information on these agreements to other groups and DDI Alliance committees A goal is to finalize a document that takes into account the agreements made regarding the MRT approach. The document about agreements which will represent our proposal for the DDI4 core, will be developed and sent to the SB and EB for their approval, as well as to other groups. Achim and Wendy: The timeliness of this document should be decided on the basis of decisions regarding the work of the group. Status: Agreed 8. Identification of issues which can be worked on in the next couple of weeks independently of group meetings. - To do for the next meeting (2019-01-20) Hilde: Will post the minutes Arofan: Will prepare agenda for next week with input from others and send out invitation to the meeting to the srg list with agenda and meeting link prior to the meeting. All: Think about the open issues from this meeting. - Contributions since last week’s meeting (2019-01-09) UML tools discussions between Flavio and Achim: In an email to the srg list of 2019-01-10, Flavio points out that we need to decide on a platform for developing, managing and sharing UML models. He proposes to use EA Sparx. The Canonical XMI support needs to be checked out. As a response to this Achim replies in an email to the srg list of 2019-01-15 that this topic needs to be discussed in the MRT and TC groups. Achim suggests to use an open tools solution, on the background that DDI is a standard, and we cannot risk that a DDI model can be used only in one tool, costs can be an issue regarding commercial tools etc. The Canonical DDI4 XMI has proved importable by many different UML tools. The problem is that most UML tools provide a custom XMI flavor rather than canonical XMI. Achim recommends to look into Eclipse UML tools, which have an XMI flavor that more easily can be bridged to canonical XMI than many other tools. Bridging might be supported by the Eclipse community. The Eclipse tools can do many other different things, for example to enable transformations from PIM to PSM. The slide below provided by Achim that describes possible usages of Eclipse tools for MRT purposes. See the email conversation in the appendix below for the full argumentation.
Status: Should be looked further into. Provenance/lineage and relationship with other standards discussions between Flavio and Jay: In an email to the srg list of 2019-01-11 Flavio brings up the question of supporting different types of lineage/provenance, and asks if everything we need to capture can be captured by Prov-O or if different standards are needed. Jay replies to this by providing references to a review of several provenance models, and some articles. Jay proposes further to form a provenance sub-group to look into this. He also raises the issue of DDI should copy or plug and play with other models, for example SDMX. In two different emails to the srg list of 2019-01-16, Flavio replies that he believes there would not be resources available to do the plug and play with standards, and he believes that DDI should specialize in a small, well-design and well-integrated set of classes to cover the aspects of the data (and metadata) lifecycle that other vocabularies either don't cover or cover poorly. See the full discussion in the emails of the appendix. Status: To be discussed AppendixEmail correspondences between meetings between Flavio and Achim on UML tools and Flavio and Jay on provenance and relationship with other tools: UML Tools: Email from Flavio to srg list of 2019-01-10 Hi Achim, We need to make a decision on a platform for developing, managing and sharing UML models. A well-know tool for that purpose is EA Sparx -- We use it at StatCan and in some UNECE HLG projects, e.g. GSIM, CSPA. Sparx allows users to create arbitrary views on-the-fly by dragging and dropping objects from the underlying model. This way it is possible to deal with smalls subsets of the model at a time during development, and also to target different audiences for communication purposes. It also supports BPMN. The model can be exported to multiple programming languages. Here you will find some pricing information for the cloud version: https://sparxsystems.com/products/procloudserver/purchase.html This is for stand alone licenses: https://sparxsystems.com/products/ea/shop/index.html I guess the big technical question, beyond design capabilities, is which version of XMI is supported to make sure we can import/export the model to other platforms. There is some information here, although not conclusive: https://www.sparxsystems.com/enterprise_architect_user_guide/13.5/model_publishing/exporttoxmi.html We can always test it and ask Sparxs for more information on their XMI support. Best, Flavio Email from Achim to srg list of 2019-01-15: Hi Flavio, Thank you for bringing this up. This will be a question to be discussed and decided by the new MRT group and the TC. DDI claims to be a standard. In this sense we should try to use a solution which is open for different usages and different users. We should avoid any dependency of a specific tool. I mean this in the sense that there is a risk that the DDI 4 model can only be used in a chosen UML tool. This might be appropriate to a homogeneous environment like a (large) organization. But the requirement in a standards environment is different. The DDI 4 model is a library. The library should be offered in a way that the library or subsets of it can be used for many purposes. A chosen tool should not be a barrier. The Canonical XMI format proved to be able to be imported successfully in many major UML tools. In this sense, the DDI 4 as Canonical XMI would be the portable format. This is useful for people who are using directly the model with different tools, i.e. for generating a representation or combining the model with other models. The issue with the Canonical XMI format is (currently) that most UML tools don't export Canonical XMI but only a custom XMI flavor. MagicDraw and probably Eclipse are the tools which export a XMI flavor which are closer to Canonical XMI. A general workaround could be to choose a specific UML tool (or to recommend one) and to write a converter from the specific custom XMI to Canonical XMI. (I did this for the XMI flavor which is exported by Lion). This way, both would be available, a UML tool for model development and a portable XMI format which can be imported into other UML tools. Another dimension is the cost issue. Any commercial tool costs something. This might be an issue in the standards environment. Enterprise Architect versions start at 229 USD; additional costs apply to software updates. Enterprise Architect exports to the UML/XMI version 2.4/2.5. (UML 2.4.1 seems to be the most implemented version, 2.5 is the latest.) The issue is that the exported XMI flavor can't be imported in other UML tools. Only MagicDraw offers a custom import of Enterprise Architect XMI 2.1. There might be possibilities to get free licenses from commercial tools for standards development. I heard that regarding MagicDraw. The issue here is that companies would probably offer only very few licenses. This way, not the whole MRT group could use the UML tool. Furthermore, other users of the model would need a paid license to use the model. The free and open-source tool Eclipse Papyrus seems to be a good choice. I suggest to look into the Eclipse UML tools in general. Eclipse UML tools use an own custom format for serialization of models, EMF Ecore (Eclipse Modeling Framework), which is available as XMI. A converter would be required for transforming the Ecore XMI format into Canonical XMI. An additional Ecore serializer could be written for Canonical XMI. This might get support from the Eclipse community. The whole Eclipse UML tools landscape offers much more. There are tools based on the OMG standards QVT Operational (model to model) and MOFM2T (model to text). These tools would enable a transformation from PIM to PSM, and generation of representation encodings (like XSD and OWL). I looked into this a little. My thinking is described in the attached file. There are Eclipse tools like EMFStore ("repository to store, distribute and collaborate on EMF-based entities (a.k.a. data or models)") and EMF Compare (comparison and merge facility for any kind of EMF Model). It sounds promising but I didn't have a closer look into this. It would need more exploration. The DDI 4 model uses only a definitive subset of UML class diagrams. This approach builds the basis to create a robust and easy-to-use model which can be used in multiple environments and which can be represented in multiple encodings (representations). A similar approach should be used regarding the UML tool, i.e. using only core features of the tool. This approach can avoid dependencies. Cheers Achim Provenance and relationship with other tools standards Email from Flavio to srg list of 2019-01-11 I mentioned in the MT call that we needed to support different types of provenance/lineage. In particular, I'm interested in the so-called why and where provenance. For definitions, please see "Provenance in databases - why how and where - FTinDB 2009" (attached), Sections 1.1.1 and 1.1.3. There are many other references, including the original Buneman et al. paper, but this one gives the gist of it. Can we represent everything we need to capture these types of provenance with Prov-O or other standards? If yes, how? Else, what is missing? Food for thought. Flavio Email from Jay to srg list of 2019-01-16 Here is a review of several provenance models including the so-called W7 model that Flavio is interested in: http://dcpapers.dublincore.org/pubs/article/viewFile/3709/1932 Here are a couple of articles that align one of these provenance models — PROV-O — with sensor data description and the Internet of Things (IoT): Sensor Data Provenance: SSNO and PROV-O Together at Last Provenance in Systems for Situation Awareness in Environmental Monitoring I imagine, in line with suggestions made by Arofan, that we will want to form a working group on provenance that will make recommendations. I am thinking that the provenance discussion also raises a larger modeling issue: does DDI intend to copy or plug-and-play other models? We have had this discussion before with Dublin Core. But perhaps we may want to revisit it. That’s because now in DDI 4 we have to decide about SDMX. Because of ongoing UN and EU work, SDMX aggregate data description is sometimes a requirement. In DDI 4 we can continue with the nCubes we currently support in DDI 3.x and perhaps perform an SDMX transformation, we can copy “essential" parts of SDMX or we can perhaps plug-and-play with SDMX. This is really a good use case for thinking about how in the future DDI plans to align itself with other models and standards. Email from Flavio to srg list of 2019-01-16 Thanks Jay. I need to dig deeper on your references to see whether W7 describes provenance at the datum level. Either way, the first reference is a great summary of approaches. Regarding your question about whether DDI should copy or plug-in other models, I tend to lean towards the latter. The large number of use cases and vocabularies out there, most of which are under active development, makes it unfeasible for a small team like ours to replicate in DDI. Besides, there is no need to. We just need to understand the use case, the existing vocabulary we'd like to integrate, and create some minimal anchor objects, if necessary, to be able to plug the vocabulary in. I believe DDI should specialize in a small, well-design and well-integrated set of classes to cover the aspects of the data (and metadata) lifecycle that other vocabularies either don't cover or cover poorly. My five cents. Flavio Email from Flavio to srg list of 2019-01-16 Another vocabulary we probably need to integrate with is PMML, for predictive models: http://dmg.org/pmml/v4-1/GeneralStructure.html Here is an example of what the model looks like, from a work some folks at StatCan are doing on the health domain: https://github.com/Ottawa-mHealth/predictive-algorithms/blob/master/CVDPoRT/Reduced/Female/model.xml Flavio |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Arofan, Wendy, Flavio, Larry, Dan G., Jay Technical Business requirements: Technical Modeling Style requirements Organizational design Patterns to help in the tooling so to reflect the pattern base in the representations Arofan's email summarizing business requirements I volunteered on the just-ended call to send out an e-mail regarding the business requirements activity which came out of the Berlin Sprint discussions. Until we organize more formally, this will just be a topic on this (the SRG list) and perhaps we can schedule a call if needed. (I have access to a WebEx so we can do meetings without conflicting with normal DDI calls if that helps). I would like to summarize the things that I am aware of which are relevant to pursuing the creation of a business requirements document which we can put forward for agreement: (1) I wrote a high-level document of feedback from the Cross-Domain (second) Dagstuhl week, during the Sprint. Jon has taken this and started extracting some basic scope for framing up actual business requirements. (2) Flavio has volunteered to document some of the business requirements from an official statistical perspective. Jay, as the DDI liaison to UN/ECE, has offered to help him with this. (3) Kelly identified during the Sprint that the Prototype feedback in fact contains business requirements, which we will need to surface into whatever document we create, at some point. (4) Wendy asked on today's call that we identify any areas where we think there might be dependencies/points of contact between this work and other efforts within the MRT work that is now shaping up. I can see that there will be some - certainly the requirements for the business purpose served by the UML model itself (and the style of it) are already on the table, from the Daghstuhl feedback document. I am sure there are many others. We will need to focus on this as we move forward. (5) It was also suggested on the call (was this Jon?) that the whole MRT proposal, along with this parallel effort regarding business requirements, needs to be presented to the leadership of the Alliance for approval/discussion. This suggests that we may need to create a very short document describing what this activity is and why we see it as important. I am sure other things may be going on in regards this work which I have not mentioned above - please add anything you see as important. I think it is early days to organize a call, especially with the holidays approaching, but we should at least try to figure out how best to move forward in the interim. One major question is finding out who wishes to be involved. The names mentioned above are clearly interested (Jon Johnson, Jay Greenfield, myself, Flavio Rizzolo. hopefully Kelly as project manager) but who else would like to get involved? I am sure this is a broader group. If you are interested in helping frame business requirements - not technical requirements - for the DDI 4 work, please respond to this e-mail. Also, if people think that an organizing discussion before the holidays would be useful, please speak up. We can easily arrange something.
Modeling technical requirements - need to provide a summary for comprehension SPARKX cloud modeling approach for UML modeling https://www.sparxsystems.com.au/enterprise-architect/cloud-services/cloud-services.html |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Larry, Dan G., Arofan, Achim, Hilde, Jon, Flavio, Kelly, Jay Proposal regarding an MRT group to replace or expand the MT What are the real next steps in December and January. Next meeting January 9 (status check) first working meeting January 16 Email from Achim prior to meeting: |
Modeling Team was on hiatus while the Technical Committee prepared the DDI4 Prototype for review
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Kelly, Wendy, Jay, Larry, Hilde Agenda: General Updates on content/files - Kelly et al (10 mins):
reStructuredText examples - Kelly (10 mins): Hilde Questions - Hilde (25 mins):
|
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Kelly, Wendy, Jay, Larry, Oliver, Dan Modifications due to model changes in documentation: Content and format updates |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Larry, Oliver, Kelly Kelly will present her organization of work so we can see where we are plugging in Some rules on what type of issues should be filed where so they get addressed by the right group Class level documentation as much as possible in next two weeks Oliver will check on the transformation issue - XML rendering of regular expressions |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Larry, Jon, Oliver, Kelly Role of dual TC/MT member is TC model reveiw - look at where you can best contribute Meeting schedule through June - We'll meeting next week and the leave scheduled for every other week if needed to verify what has been done, what's being worked on etc. Issues found during write-ups for TC Want to make sure what we have is the most accurate Documentation issues - review documents for current accuracy and move to DVG-27 DVG-27 Use cases / examples DVG-28 |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Larry, Dan, Oliver, Kelly Agenda briefly:
2) don't include the class i.e. InstanceVariable and document that this is the linking point to a larger range of packages |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Oliver, Larry, Kelly, Dan RectangularLayout becomes UnitSegmentLayout Larry made change and will follow-up with documentation search and fixes If we are going down to the datum and data point we are missing describing the Set of Units. We can say what the population was but we don't have a means of subsetting by definition. Want to lay out the issue. How would this relate to where VariableStatistics would need to be attached. Possibilities would be use of IdentiferViewPoint, Transformation Processes, possible of creating an Index or other means of addressing this. We want to be clear on what the prototype does, what it doesn't do, and issues. How far up the Variable Cascade Use the Variable Cascade as a central hub of where everything plugs in thereby facilitating connection to different parts. Model hangs together how extensions can plug in (different capture modes, different storage modes, etc) Workflow work is now stable - Business Workflow |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Larry, Oliver, Dan, Kelly Data Description: Rectangular - does it also include a CSV as long as all lines have the same amount of columns SingleLogicalRecordFile - Flat? UnitRecordFile? MulitpleLogicalRecordFile - Hierarchical/Relational Two things: FlatSegmentLayout Prototype - Cube - dimensional store ACTION: Vocabulary agreement: Items 1 and 2 under Agreed are agreed Under Questions:
How does verification of use cases move into the documentation? |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Jon, Oliver, Larry LOGICAL and FORMAT When Jay looks at the model now and the bindings Deirdra has been working with are out of synch and there are still some issues to finalize before entering the changes in Lion. There are lots of collections that bounce up against each other and this is being simplified. Jay has been sending out models of the agreements. He has been testing this model and making examples. DMT-176 One of the big changes we decided that Viewpoints hung off the Unit Record Relation Structure. There are no Viewpoint relation records Simplification resulting from mechanical entry of collections - showed up a number of duplications of activity. These have been cleaned up. Language of object - DMT-177 Move CDE to separate package Workflow/Process - NEXT MEETINGS Get data description nailed down in the next 2 weeks. Need to finish views and enter them by end of January 31. Jay and Larry will talk about how Format relates to logical and present next week. |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Larry, Jay, Dan, Oliver DMT-182: Format structure issues raised in working on Use Cases. Data Description issue will discuss at next meeting. Darrin's example - can Jay see what you're doing - wendy email get his RDF Wendy will go through remaining views and potential view and draft for discussion DMT-148 - looked at specific issues (skip those in Qualitative) Final review piece is to identify those ComplexDataTypes that are total orphans - find them and isolate - Oliver will write script for validation of this problem Script to identify orphans in general - with package information - Oliver ISSUES for resolution before end of January Extensions to Workflow for Prototype - Jay will gather information, we'll create issue and determine what needs to be discussed Add lists of classes needing documentation in other packages in Prototype |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Larry, Dan, Oliver, Kelly Workflows: PENTAHO etc. start with metadata and produce the transformation using that as a driver. Suggest the use of a MetadataDrivenAction. Add the ability to add a correspondence table which would hold the relationships used for recode. The user creates the correspondence table (ex. the IPUMS transformation table). Addresses Joins, recodes, renames Question: Are you aiming at being able to roundtrip and generate the PENTAHO from the DDI? Yes, we can do that. It's JAVA based. These systems also support formulas and can run scripts. They still want to use their statistical packages to do certain things. Don't want to do statistical analysis in a data management environment. Every time they changed data management they had to rewrite the STATA code because no one could understand another's code. If you capture the algorithm and generate the code as opposed to trying to derive the algorithm from the code. You can see what is going on within the eventual code. Jay will send to Wendy and Wendy will put in to verify that what Jay is proposing is clear. LION content: Jay to send Kelly a write up of the decisions made in Dagstuhl regarding the logical data description, some of which have not yet made it into the model. Wendy to follow up with Jay about creating an issue for integrating these decisions in the model. |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Larry, Jay |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Larry, Dan, Oliver DMT-141 - change xs:string to ECVE (entered) |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Larry, Jay, Oliver Annotation Document Information Implications for document information - none at the moment - could leave as in and recommend that for certain RDF instance bindings Right now document information is put into all Views - should this be a deliberate selection based on the need for a persistent document rather than an interchange FOR PROTOTYPE: How would you use this information in a sparkle query? What you could do for instance if you already know something you want to query based on a study series. You know about this one document and you want to find the study identification to find variables. For most cases you would just use it for retrieving the provenance information on the metadata. Annotation usage: What annotation apply to - the metadata object
|
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Larry, Dan G., Oliver ACTIONS: Dan G. - review the issues at the bottom of the list with ? (100, 115, 141) and confirm that they have been addressed by Data Description. Any documentation should be added to these issues over the next month or so in order to make sure it is available -
OK resolve Wendy - will try to get geography structures ready to look at next week Geography is almost done. It extends CodeList: 2 questions 2) Would an abstract base for a CodeList/Statistical Classification/etc. be easier to handle (limits extension depth, opens up for other forms of signifier/signified options) DMT-159 - resolved Annotation issues: Access issues: access to data, access to metadata, persistent access restrictions/rules, local restrictions/rules In RDF you'd have some general information about a triple store but would not be able to distinguish different sources that different triples hand from. If you do quads you can have identification information on the triples. You are not able to say "give me the document root" you'll always land at the level of the triple store not the package of related triples. https://www.w3.org/2001/12/attributions/ RDF provides not model level division between data and metadata Jay and Oliver will work on this Workflows in on the agenda for next week |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Larry, Dan G., Oliver spreadsheet used in discussion Assignments for next week Dan G. - review the issues at the bottom of the list with ? (100, 115, 141) and confirm that they have been addressed by Data Description. Any documentation should be added to these issues over the next month or so in order to make sure it is available All - DMT-157 I've reviewed and made comment so I think we can agree and resolve it. If there is no descent then I'm happy to enter that change. Workflows in on the agenda for next week Wendy - will try to get geography structures ready to look at next week All - review items associated with Annotation/Citation, we need to determine what must be addressed for prototype and what if anything can be delayed. Also, what is modeling and what is documentation. Oliver - add an issue to this Annotation/Citation set that addresses the issue identified in Codebook meeting as well as fuller documentation |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Larry, Oliver, Dan G. Codebook will be reviewed for new classes, changes of identifiable to Complex Data Type, etc. Change name of CodeItem to CodeIndicator (done) CodeList - will always have contains with CodeIndicator and may have isStructured: ClassificationRelationStructure which points just to category (done) Instructions should indicate that you must use contains: CodeIndicator for simple and structured CodeLists. If the CodeList is structured use isStructuredBy: ClassificationRelationStructure to provide additional information on complex structure (done) LogicalDataDescription |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Larry, Jay, Oliver XMI and definition of default values and regular expressions - Larry will send Oliver some XMI examples Start entering following Flavio's review pattern and then realize where needed Add ability to create a variable group and a statistics group (has to relate in some way to a data file) Codebook is down to finishing up relationship to DCAP and whether to include a relationship to Concept |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Larry, Dan G., Oliver Codebook View Review: Can I enter collection and realization changes for those classes used by Codebook |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Oliver, Larry, Dan G. Current state of Collection revision:
Where do we go from here from this
We need to have a clear workplan and priorities over the next 18 months As we're working on this can we create mini-examples. Oliver will create a means for us to make builds. |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Dan G. Discussion of collection realizations:
Jay and Dan G. will walk through the realizations next week. Will also have a discussion during TC meeting period this week as there is no TC meeting Wendy will review what extending Statistical Classification from ColeList would look like. Also explore implication of extending Unit Type, Universe, Population from Concept |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Oliver, Larry Went over emails regarding collection model and realization What needs to get done for CodeBook: Documentation of View capture: |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Oliver, Jay, Dan G. Proposed game plan discussions
Documentation of Views:
Patterns:
Signification Pattern (new issue DMT-137 describing task).
APPROACH:
|
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Dan G., Jay, Larry
Add to NewCollection
|
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jon, Jay, Oliver, Dan, Larry
Collection Pattern:
ACTION: Wendy will review work and draft summer work plan and send out for comment |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jon, Jay, Dan G., Oliver, Larry
Discussed and determined to be part of a larger issue on access restriction
Remaining
|
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Oliver, Jay, Larry |
| Expand | ||
|---|---|---|
| ||
ATTENDEES: Wendy, Jay, Larry Collections
Sprint prep:
to do before sprint
|
...