...
| Warning | ||
|---|---|---|
| ||
Materials from External Review work at Dagstuhl Sprint |
| Expand | ||
|---|---|---|
| ||
DDI4 Virtual MRTVirtualmeeting 2019-01-30Agenda (as in invite of 2019-01-28)Goal: To have a draft program of work for NADDI Sprint (to submit to EB), and an initial list of proposed tasks.
Suggestions: - Documentation of datum-based model application to examples of event data, aggregates, etc.
- Existing modeling technical requirements/issues
- Others
- Are there ideas/candidate tools which need to be written up/further explored?
- Identify tester and potential testers (We may not get this far, but if we have time it would be good) Minutes DDI4 MRT Virtual meeting 2019-01-30Attendees: Achim, Arofan, Dan G., Flavio, Hilde, Jay, Larry, Oliver, Wendy Apologies: Jon 1. Description of what is needed for organizing NADDI Sprint (from Achim):A goal for the meeting is to have an agreed document regarding the NADDI Sprint planning ready to send to the AG to inform their discussions at their next meeting, and further to apply for funding of the possible sprint. Achim prepared and sent out the document ‘NADDISprintPlanning.docx’ to the srg list in advance of the meeting. This is a shell document where some content of the document needed to be filled in or reviewed and agreed while the meeting. The meeting was structured in three parts: 1) Topics for the possible NADDI Sprint; 2) Review of possible participants and funding; 3) Other organizational issues regarding the possible NADDI Sprint. 1) Topics for the possible NADDI Sprint (see point 2 in the agenda)a) Documentation of datum-based model application to examples of data structures (to be discussed and agreed at the meeting which data structures to focus on at the Sprint). b) Discussion and possible resolution of structural model issues:
Status: Points a) and b) agreed as topics for the possible NADDI Sprint. Discussion and agreements regarding example data structures a) Example data structures (point a) were discussed after the structural model issues (point b). The discussion regarding which data structures to focus on as examples at the possible NADDI Sprint was centered on whether to focus on common vs. complex cases and corner cases. Dan G. pointed out the importance of modelling complex cases, as more common or simple cases would then be solved at the same time. Others pointed out that issues could occur even if a similar approach is used. Agreement was reached to focus on the common cases as a preparation for the possible NADDI Sprint. Status: Agreement was reached to focus on the following common data structures for the possible NADDI Sprint:
Arofan and Wendy pointed out that the Variable Cascade documentation (provided for example in the Variable Cascade presentation from the Dagstuhl workshop DDI Train-the-Trainers 2018) indicates the style and level of information needed for documentation. Status: Wendy will add this as a prototype review comment. After NADDI further data structures may possibly be explored, for example NoSQL (non SQL) data like Hadoop data, graphs etc. Status: Agreed In the Appendix an example from the discussion provided by Larry is found. Discussion and agreements regarding structural model issues b) Structural model issues (point b) were discussed before the example data structures (point a). Conceptual resolution/MRT: Jay brought up the issue if structural issues could be resolved conceptually or by using the MRT approach. Flavio pointed out the need to look at many different examples to check out structural modelling issues. Achim indicated this could be a topic for the possible face to face meeting and something for a work group to focus on in advance. Complexity of the model: Flavio commented that the model is complex because it is made complex. It has multiple levels and covers both common and domain specific needs. To simplify the understanding, some of the content could for example be hidden for specific user groups. Achim asks if the model can be improved by focusing on questions like:
Work regarding the complexity of the model could be done in advance and brought to the sprint. Review of views: The revision of Views is important. Achim points out that even a simple view like the Agency view drives in a lot of classes. Flavio points out that Views are complex because they currently are designed to cover multiple dimensions. The Classification View is for example meant to cover reuse, classification management and publishing. This and other views would need separation into smaller sets to be easier to understand. Larry expresses that the model currently is highly connected but that good documentation can help the understanding. Status: Agreement to focus on the four bullet points under b) above for the planned Sprint. Tasks should be broken up as much as possible. Smaller groups could work on each of those and get back with a proposal for the full group after a week or two. A specific person should be responsible to follow up on the work on each task. 2) Review of list of possible participants and fundingThe following agreement was made: The following people would be available in person for this meeting (their need for funding in parenthesis):
Most of the people would need funding from the DDI Alliance as specified in the NADDISprintPlanning_1_0.docx document. Oliver Hopt would be available by phone. 3) Other organizational issues regarding the possible NADDI SprintPossibilities for meeting location and lodging have been checked out and booked by Flavio and Achim as follows:
Two documents are sent to the AG for their feedback prior to their next meeting (also sent to the srg list):
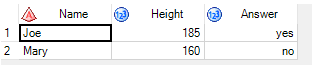
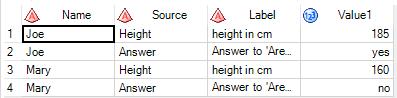
Further follow-up is required regarding organizing the start-up of the work, and making plans for what needs to be prepared in advance of the possible NADDI Sprint. AppendixExample from Larry related to discussions of point a): With the ability to describe data at the datum level DDI should be able to describe data like that in the following example through transformations from traditional rectangular (wide) layouts into key-value (tall) representations. DDI4 can currently describe the data in the wide layout, but, though we have discussed how to do the tall representation, that work has not been completed in the model. Wide data table: Corresponding tall representation: Transformations between these layouts are common in data software packages. The SAS code below shows the transformation from the wide to the tall. Note that in the Tall representation the column Source is a pointer to a variable in the wide layout. The column Value1 is not a traditional variable, in that there is no one value domain or concept associated with the whole column, instead those things depend on the pointer in Source. If we can properly describe datum level metadata we should be able to describe the value domain and concept associated with the “yes” category label (which is actually a code of 1 in the SAS dataset) in the Value1 column. We should also be able to describe the meaning and units of measurement of the value 185 in the same column. Proc format; value yn 1="yes" 2="no" ; /* example rectangular file */ data fooWide; input Name $ Height Answer; label Name="Person name" Height="height in cm" Answer="Answer to 'Are you hapy?"; format Answer yn.; datalines; Joe 185 1 Mary 160 2 ; run; proc sort data=work.fooRect; by Name; PROC TRANSPOSE DATA=fooWide OUT=WORK.fooTall(LABEL="Transposed WORK.FOORECT") PREFIX=Value NAME=Source LABEL=Label ; BY Name; VAR Height Answer; format Value1 yn |
...