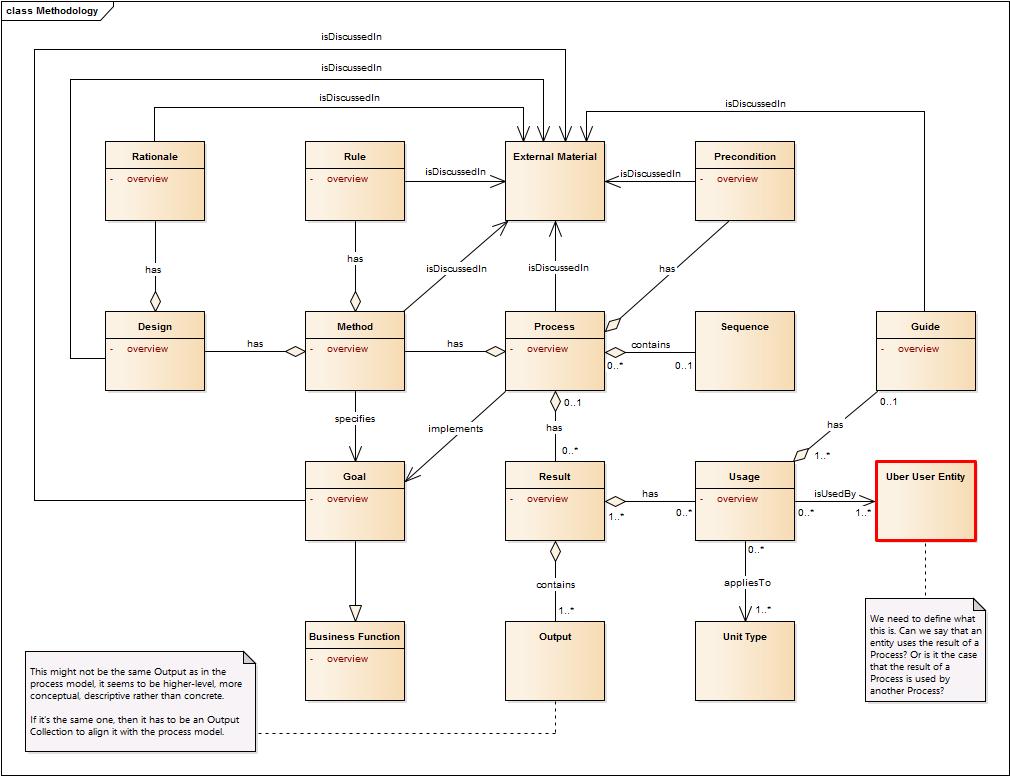
The work that we're looking at at the moment is how far we can go with this rationale model. Yesterday we applied this model to weighting. We tried to apply this to sampling. The recognition was that "x" is an outcome. For sampling it's a selection since sampling is the design and process part of the model. "Variable" - is it necessary? Or should it have a different cardinality of 0..*? Is this single-stage or multi-stage? It does account for the multi-stage and it's executed more at the "design" part. The description is the overall process is in the Design, but the execution is in the Process by a set of process steps. The Sampling Model would be a description of the Design. The questions for today and tomorrow are to break out the Design and Process boxes. Could you do something similar to fit in the Methodological Model for Coding and Weighting? Concentrating on the Design box. Can we standardize the Design box for feeding into the Process box? There may be overlap with Instrument. Looking at Arofan and Jay's document from Dagstuhl. Here we're saying what we're going to in a method for a Process. This may be useful to look at in the InputType, InputInstance, Citation, OutputInstance, etc. This is very similar to GSIM (in the central column). We should really look at GSIM. One takeaway is that you can describe a method at any level of granularity. You could have a process step design that says you're doing a multi-step thing, and then the process model wouldn't go down and describe each stage specifically but the entire process of stages. In the document there's an early example that looks like a higher level example of Process that each box could be a Process Step and is similar to GLPPM. Let's take a quick look at GSIM and Instrument and see if we're getting similar things - as Barry is seeing a lot of overlap in Instrument. Looking at the GSIM Process - We didn't include Process Control Design but we need to in some area of the Process.
- Each Step can have a specification, and so we get into the distinction of human and machine readable and that's where we can get into the distinction of the boxes in this model.
- The key pieces to this Model is in the ProcessInput/Output and Process Step Instance. These may be in the Instrument work as well.
- We may not need to worry much about the conceptual and implemented parts now.
Can we describe methodologies in terms of design in this way or not? Can we describe weighting and coding in a basic input and output approach? Barry has already used Instrument to create what is a Methodological Design. - A questionnaire design has set a of Process Steps and captures the idea of what we're looking for.
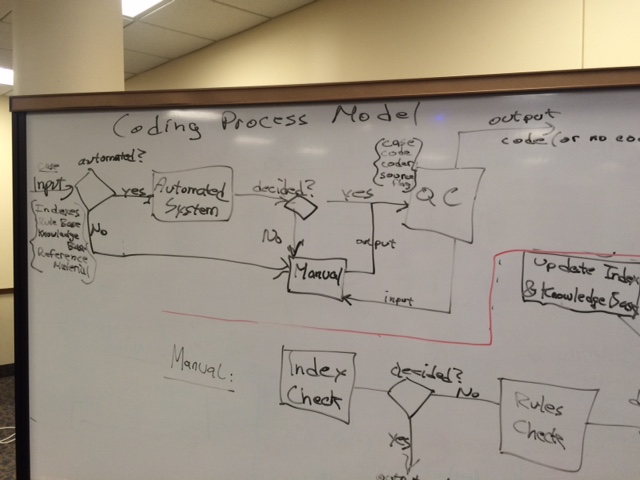
Let's map out a Coding and Weighting Process. CODING: Develop "index" mapping phrases to codes Develop Rules for disambiguation (where would a body of knowledge go in DDI4) Rules for difficult cases Identify people roles: - Vocabulary development
- Training
- Supervision
- Coders
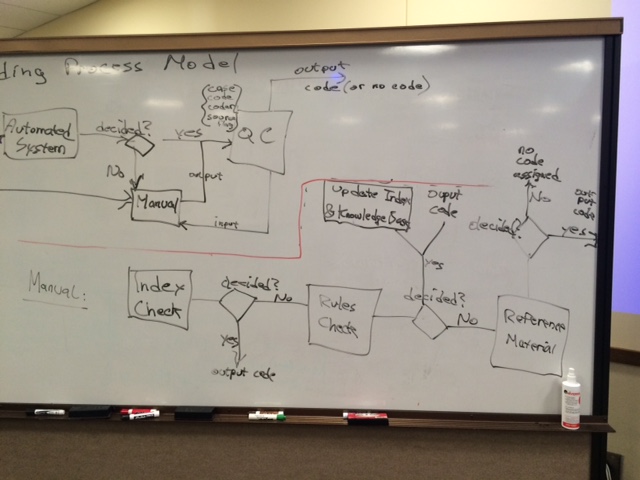
Manual process inform machine learning process Automated system first then manual Update of machine learning database QA on sample of coded data Identification of training needs Conclusion: This can be done at a high level, but a real question is whether someone would want to; this is quite difficult. Narrative description of a Coding Process Model Pre-Inputs - Classification
- Indexes
- Rule Base
- Reference files – more detailed information for hard to code cases
- Knowledge base - drives automated system
Input a case (input = piece of text) Check for automated system - Yes send to automated system
- No send to manual system
Automated system - Automated system decides case –
- Send to QC system
else - Send to manual system
Manual system input indexes - Split – multiple coders/assign case to coder
- Each coder – index check
- If Decided? Send to QC
- Else rules check
Rules check - If decided yes send to QC and index update
- Else reference material
Reference Material - If Decided yes (send to qc and index update and knowledge base update)
- Else no code assigned
QC System (inputs: case, code assigned, source flag) - Decides – evaluate or pass
(Images from board: Image 1/Image 2) | ")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}