Data collection across a diverse network of data providers (group 3)
Systematizing and sustaining data collection across a diverse network of data providers
Jim Todd, Doug Fils, Jay Greenfield, Simon Hodson
Work is now in Google doc at: https://docs.google.com/document/d/1ilnUJTnArU2bCzODZIQTsvDt0t6l73V0FbGfVX4bVgE/edit?ts=5d9f4473#heading=h.m7ver2ypep5m
First PM Session, Tue 8 Oct
In which cells in the matrix are we working?
In relation to which stage in processing does this relate?
What level of guidelines are we working on?
Steps from the presentation about topics
- Diverse sources could include survey data, clinical data, events, etc.
- Look at equipping and building capacity for providers
- Look at motivating data providers
- Allow data providers to retain ownership of their data/metadata and the reporting process
- Allow for cultural factors in establishing a sustainable solution
- In the Interoperable and Reusable areas, looking at the Harmonization/Transformation stage, for producers of integrated data sets and the providers of integration tools.
Resonates with some of the work that Doug is doing for NSF and in relation to EarthCube. Jim has tools which can index data sets.
Work of the Alpha network would benefit from these recommendations. 10 contributors in the ALPHA network. Current data exchange and integration based on ALPHA data specs. Use certain algorithms and procedures, now automated. Have been doing work facing the providers and users to assist with how they provide their data, metadata and
Jay works with Jim on ALPHA network. Has a history of putting together cohorts for data sources, in health and social sciences in US.
Alpha network is looking for datasets that have longitudinal data about HIV instances, outcomes etc. Cross sectional data like DHS.
Access controls as a means of reassuring data contributors. Agreement with the data aggregator that part of the data can be extracted or accessed.
To what extent does INDEPTH and ALPHA conform to FAIR principles? ALPHA is only discoverable by members. Documentation and provenance of data is rich. Data can be cited.
DSS data is findable and accessible.
What is the motivation for contributors? Some funding provided, publishes papers and provides results for which the contributors get credit. Outcomes are potentially improved response to HIV in the partner countries.
Have access to clinical records in the countries that are part of the ALPHA network. Record linkage between visitors to clinic and record in the survey data.
What is the goal? To make metadata available for discovery? Data itself would not be accessible.
Alpha data is an extract from cohort data. Anonymisation is the substitution of an ID - cannot identify an individual person in a cohort. But the linkage with other information, might allow deanonymisation.
Metadata allows users to form queries to analyse data. In principle, members of the ALPHA network could monetise access to the data.
Data for NCDs? Infant vaccination rates, mortality? Neglected tropical diseases.
Indicators for universal health coverage. Government can identify what proportion of population is affected by given conditions. For prevalence this is possible, because the governments can access the DSS and establish this. But for diseases other than HIV, the data has not been optimised to perform more sophisticated analysis by linking to clinical records.
Currently a lot of this data is not conformant with FAIR principles. SAPRIN http://saprin.mrc.ac.za/ is collecting data from SA population surveys.
Alpha network is a project, currently funded by Gates Foundation and Wellcome. Currently has 18 months remaining.
Alpha network currently promotes FAIR to the extent that the data is findable and accessible. Interoperable within the system.
Alpha aims to make the data FAIR through making the processes transparent and reproducible.
Issue of different definitions of household. Different definitions used across the six countries and the 10 sites in the Alpha network. Does this represent different social realities or loose definitions? Possibly either or both.
Promote principles and good practices.
Prototype that demonstrates the realities.
Alpha++
If we were to make this happen, we would need to put in place the following.
Would benefit from engaging / liaising with SAPRIN.
Alpha itself is interested in analysing the HIV data.
Cross domain initiatives maximise the investment in the DSSs. How Alpha can be expanded / lessons can be learnt to create something that addresses a broader range of communicable and non-communicable diseases.
What are the other necessary data sources? What are the necessary recommendations (and cultural incentives etc) to encourage those data sources a) to allow their data to be extracted and ingested; and b) to follow good practices in making their data accessible / extractable.
Vision and Strategy for the African Open Science Platform: https://doi.org/10.5281/zenodo.2222418
A data model for demographic surveillance systems: https://www.researchgate.net/publication/228705686_A_data_model_for_demographic_surveillance_systems
Can be described using DDI - provided a use case for development of DDI 4.
Important concepts include episodes and events.
Original model came out of INDEPTH. Was never fully documented. Chifundo documented it using DDI 2 codebook (Nestar). Not clear how many DSS sites have done the doucmnetation for their DSS data.
Use case for DDI and DCAT etc to be tools which will enable Alpha and Alpha+ to be FAIR.
Data cleaning is done at the point of extraction. Recommendation to DSS centres
Vision Alpha+
- increases the use of DSS data
- DSS data is being collected but not used for communicable and non-communicable diseases
- provides data for communicable and non-communicable diseases
- reuses and improves Alpha processes
- Alpha provides a model for data collection
Lessons learnt from Alpha
- recommendations to DSS data providers
- lack of documentation
- XXXX
Principles that are relevant
- a data model for population studies exists
- DCAT and Schema.org can be used to help findability
- DDI 4 can be used for provenance documentation (for the transformations)
Proposal
- More specific than GoFair
- Begin with a concrete proposal for Alpha++
- Extract this in the conclusion:
- A general model we can use to create networks across Africa
- What are the principles of this model
- What is the logical definition
Notes for Vision
- Data sources: DSS population surveys, clinical trials, research projects, clinical visits.
- First step is to repeat the Alpha process with DSS and clinical data. Vision to expend to other data sources.
- Need for African capacity, Africa based data centres.
- Current level of capacity suggests the need for a hub model. Hub model sets the lowest bar for data extraction and integration for each of the DSS hubs.
- Expand to include data relevant to other communicable and non-communicable diseases (i.e. addressing SDG 3.3 and 3.4)
- Desideratum for DSSs and similar stakeholders is to build capacity for better use of the data.
- Desideratum for LSHTM researchers and Alpha community is to reduce the time spent on data cleaning and wrangling.
Proposal for ALPHA++
0: Introduction
This document presents a vision for an ALPHA++ data service. Building on ALPHA, this service would aggregate data from a number of sources (primarily cohort population studies and clinical data). The data would relate to significant communicable and non-communicable diseases and will allow researchers, practitioners and policy makers to make evidence-based interventions to address health issues in a range of African countries, in support of SDG 3.3 (end epidemics of communicable diseases) and 3.4 (reduce by 1/3 premature mortality from non-communicable diseases). The proposed service will learn from the lessons of ALPHA and other initiatives and will use best practices for data extraction, integration and documentation. As well as the direct benefits for health related research the initiative will have a number of important additional benefits. It will demonstrate the benefits of the adoption of FAIR principles, such that data are Findable, Accessible, Interoperable and Reusable. It will provide a case study in the effective and efficient creation of an African-based infrastructure and the wider benefits of the capacity building that enables this. The infrastructure will facilitate greater use of the data, and make it know to policy makers in participating African countries as a source of data to answer important development indicators. Furthermore, ALPHA++ is proposed as a cross-domain research initiative under the umbrella of the African Open Science Platform: consequently, it will benefit from coordination as part of that programme and serve to provide important lessons for other related projects.
Additionally, we draw broader lessons and make recommendations for the adoption of good practice in cross-domain initiatives and in data initiatives in Africa. This service will demonstrate the steps needed to bring together data as a shared resource for answering wider questions.
1: Vision - why is the initiative needed and what would it do?
ALPHA extracts data from existing health and demographic sentinel surveillance sites (HDSS) that is relevant to the study of HIV in the population, and then combines these data with clinical data relating to HIV services. These data are extracted and transformed in the sites collecting the data and then transferred securely to the London School of Hygiene and Tropical Medicine where it is used by project partners. ALPHA has therefore established an effective mechanism for data extraction which has now been semi-automated.
This presents us with a remarkable opportunity which is described in this proposal. The vision is to contribute substantively to the Sustainable Development Goals 3.3 and 3.4 and to help provide the required evidence to show the reduction in communicable and non-communicable disease in low and middle income countries. This will be done by using existing sources of population and clinical data, that relates to these pathologies, and making them available under controlled circumstances. The project will build on the experience gained by ALPHA, further refine and improve these processes with best practices from the FAIR and data science communities, and apply them to a broader range of data relating to tuberculosis, malaria and neglected tropical diseases, hepatitis, water-borne diseases and other communicable diseases, as well as cardiovascular disease, cancer, diabetes or chronic respiratory disease.
As with ALPHA, data will be extracted from HDSS population surveys. The data model and processes will allow easy combination with other data sources including clinical data, clinical trials, research projects and so on. The project will demonstrate the benefits of applying good practice for FAIR data and in particular:
- to provide rich metadata to enable users to discover data resources and to assess their utility before access is granted;
- to ensure maximal interoperability and linking of data from various sources to allow sophisticated querying and analysis;
- to provide detailed provenance and process information to ensure trust, reliability and maximal usability of the data.
ALPHA data is currently hosted and made available to project partners from LSHTM. ALPHA++ would develop a service hosted in Africa. This is essential in order to ensure that capacity is enhanced in African institutions to curate African data assets. Important benefits of the project therefore include:
- the enhancement of capacity for data stewardship in the African host institution;
- the development and implementation of a sustainability model for the ALPHA++ service;
- training initiatives for data stewards and for researchers to ensure maximum usability and reuse of the ALPHA++ data.
Important considerations will be the access rules for the data and the partnership agreements that relate to this. ALPHA data is de-identified but some tables would, if made completely open, in theory enable the identification of individuals. For this reason, ALPHA data is currently restricted to partners who have signed the necessary access agreements. These partners include the HDSS data providers and affiliated universities. ALPHA is currently exploring how to maximize reuse by making certain tables openly available.
ALPHA++ would seek to increase reuse and impact in a number of ways:
- by expanding the number of partner institutions;
- by carefully and responsibly making the maximum number of tables open, consonant with protecting individual's identity.
ALPHA++ will aim to maximise the benefits and incentives for data providers by continuing and strengthening the agreements about recognition and citation when ALPHA data is used. Training initiatives in stewardship and analysis will also benefit data providing institutions.
Ensuring the effective resourcing and sustainability of the ALPHA++ data resource and service will be essential. Therefore, ALPHA++ is proposed as a project that will form part of Strand 4 of the African Open Science Platform (AOSP) initiative. Strand 4 comprises high impact, cross-domain and data-intensive research projects that as well as having significant research and policy impact in their own right will also demonstrate the benefits of the coordinating support provided for the Open Science and FAIR approach provided by AOSP. ALPHA++ is a perfect fit for this strand and would benefit from the proposed sharing of research infrastructures (Strand 1), of data stewardship and analysis resources (Strand 2) and training activities (Strand 5). ALPHA++ will have to examine available income streams and develop a business model for the ongoing service.
2: Lessons learnt from ALPHA and INDEPTH
INDEPTH established a network of health and demographic sentinel surveillance (HDSS) sites, and an infrastructure that supported some data processes from those sites. HDSS are longitudinal population cohorts which follow people through life events - births, marriage, migration and death - usually in a defined geographic area (Ref INDEPTH Model by Justus Benzler, Kobus Herbst & Bruce MacLeod). Most HDSS include periodic surveys on the health of people resident in the area, with different HDSS collecting data on different health conditions - childhood malaria, TB and leprosy, HIV and sexually transmitted infections (STI). By 2015 there were more than 35 HDSS across Africa, with many countries supporting 2 or more HDSS. While INDEPTH did not provide funds for data collection they did support the standards used by HDSS, for example through the implementation of the 2012 WHO verbal autopsy tool for the identification of causes of death for deaths in the population. INDEPTH used annual meetings to bring together data personnel (data managers, statisticians and programmers) to network and establish discussion fora. INDEPTH introduced a mini-server - iShare - as a means for member HDSS to publish their aggregate data on fertility and mortality.
In 2005 the ALPHA network was set up to bring together the data on HIV from established population cohorts. A total of 10 populations cohorts (8 of whom are HDSS within the INDEPTH network) with longitudinal population data on HIV were identified and agreed to contribute demographic and HIV data for analyses coordinated by the ALPHA network. The ALPHA data specifications defined subsets of the populations cohort data which are used for the analyses, usually not more than 10% of the total data collected from the cohort. The ETL for the ALPHA data spec started with manual application, but has developed into a semi automated Pentaho Data integration (PDI) process. The main data spec is the demographic residency episodes, which show each individual resident in the cohort and the time period lived in each location, and that is contributed by all partner sites. Other data spec include HIV testing, HIV treatment and sexual behaviour (including partner loops). The pooled data allow comparative analyses across 10 sites in 6 countries, which can show differences in HIV prevalence and incidence, survival of people living with HIV (PLHIV) and access to HIV services. These supply data to provide SDG indicators, and to answer additional questions of relevance to funders such as UNAIDS, Wellcome Trust and BMGF.
Partner sites with population cohort data join INDEPTH and ALPHA for the benefits that come from the collaborative work. These include support and advice on data collection, data management, and processing. It includes introduction of sites to the latest tools, questions and services, and the opportunity to discuss and consult on the way these can be used within the HDSS. There have been some financial rewards, with some money for the preparation of ALPHA data and to support data managers, but the main incentive is the opportunity to network and develop skills within the networks.
The data process starts from the raw population cohort data collected by partner sites. A mini-server, Centre in the Box, running PDI extracts the relevant ALPHA data and populates the data spec in the mini-server. External access through a VPN copies the data from the server directly to LSHTM where it is cleaned and prepared for the analyses. Discrepancies and restrictions on the data are discussed directly with the data managers in the partner sites to ensure data consistency and validity. Meta data is derived from the site specific meta data, but is currently not necessarily aligned with any formal ontology. The HDSS data from the individual partner sites, and the ALPHA data extracted from the sites, are not currently findable or accessible outside of the network members.
The ALPHA process has developed a set of specialized tasks. LSHTM is interested in the final analyses, and the interpretation of the results for national and international policy makers. LSHTM is committed to training in data analysis techniques, and in supporting further site-specific analyses. However LSHTM is not a specialist data centre, and the development of specialist data processes that conform to the FAIR principles is not easily carried out in LSHTM. The ownership, responsibility and service of the pooled ALPHA data would fit more easily into an African data hub with strong links to the contributing partner sites. The formalization of the vocabulary used in the data structures would make it easier for the data to be findable, and would also contribute to the inclusion of data from other HDSS or population cohorts where similar data are collected. Regularization of the data in this way would also make it easier to ensure confidentiality and hence enable the ALPHA data to be freely shared.
The ALPHA network have developed data specs for the pooling of demographic and HIV data from longitudinal population cohorts in Africa. The principles used in the pooling of HIV data can be used for many other health conditions, and it would be very useful if these data can be produced and made available as FAIR data. The current data are not aligned to a recognized ontology, and the use of a defined, existing vocabulary will make it easier for other population cohorts to participate in the network. The data management for the ALPHA network data has been done on the back of the project grants for the analysis, which means that it has not been given the recognition of the importance of the work. The data would be more sustainable with training and support for a few dedicated data professionals in an African setting, who would be able to develop and implement robust techniques for extraction and management of the ALPHA data, and other similar data specs. Finally integration of the data with other data sources, such as data from clinical cohorts, clinical trials, or cross sectional population data, with the same recognized ontology, would enable direct comparisons of SDG indicators, and other national markers for HIV services. These improvements in the data production and availability would help to make the data more accessible and transparent, and the results more understandable to policy makers.
Ultimately the ALPHA data needs to become an infrastructure resource, serving a network of users. In this the network can learn from the experience of H3Africa, OASP, and other data services. The objective is for this data service to become a population infrastructure resource similar to SAPRIN in South Africa (saprin.mrc.ac.za).
3: Good practices to be adopted
The current practice for ALPHA data flow is shown.
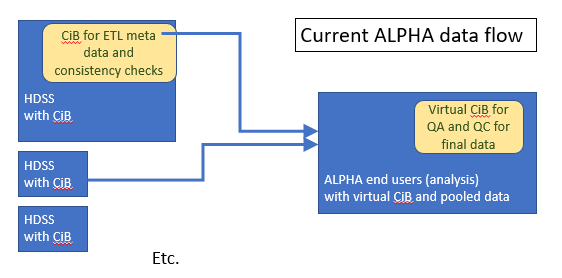
This rolls in the data consolidation, QC checks and many other aspects of the data with the ultimate analyses. These analyses provide the rationale for the data production as well as the means of production, making the whole process dependent on the end product. The role of the data hub is to recognize the value of the data in itself, and to ensure that value is located in Africa to leverage resources to further build capacity for data collection, management and analyses.
The proposed value of the data hub is shown:
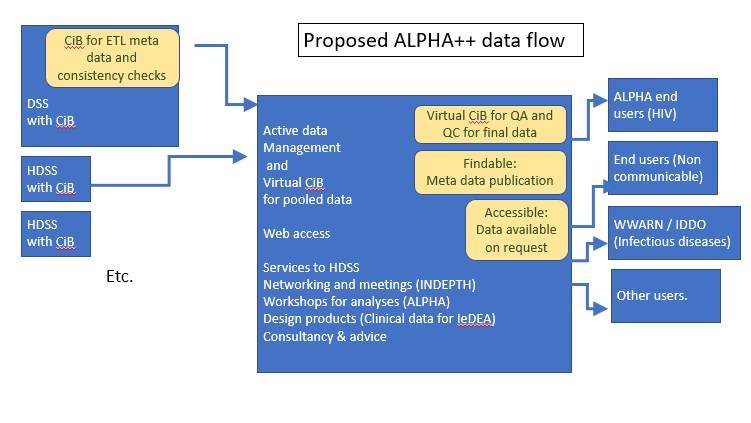
What extra value might be obtained from the proposed ALPHA ++ data hub?
- Recommendations to the HDSS and expert support for the data collection which will be especially useful to the smaller HDSS
- Mechanisms for extraction of data and documenting the meta data for the extracted data
- Mechanisms for linking to clinical records and developing the new databases required for clinical data
- Variable models / information model - variable properties together with the variables. Ensuring the ALPHA ++ data utilize the latest standards and the best practice for information models.
- Access and reuse agreements for the shared data
- More specific than GO FAIR but would benefit from such activities and promotion of good practices
- Adopt information model such as Open EHR
- What is the model that the different centres use to refresh their data?
Sustainable African Data Node
The development of data stewardship capacity on the African continent is essential if the opportunities and benefits of the data revolution are to be realised, if African scientific production is not to be left further behind and if adaptation to 21st century climate and developmental challenges is to be realised. The development of such capacity is long overdue and African currently remains dramatically under-represented in such services as Re3Data and in the CoreTrustSeal repository certification scheme. Investment in network infrastructure and the development of African NRENs along with the progress of a number of African universities and research initiatives mean that it is timely to develop research data infrastructures in Africa.
The following criteria could be used to select the most appropriate location for the ALPHA++ Data Service:
- Country served by a level 5 or 6 NREN (see https://www.casefornrens.org/documents/the_role_and_status_of_nrens_in_africa.pdf for 2016 Status - Kenya, South Africa, Uganda and Zambia)
- Research institution, university or research centre with sufficient capacity, potential and commitment to host the service.
- Support of the national government, the appropriate ministry (research or health) and ideally the national science granting council (see https://sgciafrica.org/en-za/participating-councils).
The human resource effort required to manage the ALPHA data service is currently 2FTE split over a number of actual people (managing the pentaho service, QA/QC). The service currently draws on the LSHTM IT services for the server infrastructure and access control.
The estimate for the FTE required for the expanded service is as follows:
| Activity | Human Resource Effort |
|---|---|
| Server, repository management, access controls | 1FTE |
| Developing new Pentaho services | 1FTE |
| Managing existing Pentaho service | 1FTE |
| Metadata management and QA/QC | 1FTE |
| Training, advocacy and outreach | 2FTE |
| Total | 6FTE |
Income Streams and Business Model
Setting up the ALPHA++ service would require grant funding resource, likely from an international funder. Sustaining the service would require a combination of income streams and a robust business model. (A discussion of the combination of income streams into business models for data repositories is OECD-CODATA 'Business models for sustainable research data repositories' https://doi.org/10.1787/302b12bb-en). The income streams would include:
- Support in kind from the host institution covering infrastructure maintenance costs and some of the FTE required.
- Infrastructure funding from the research ministry or granting council.
- Membership fees from partner organisations. The membership model could take a number of forms, to be explored. Options include: a) a model that provides controlled and conditional access to the more sensitive and/or enriched data; b) a model that emphasises 'club good' of participation in research projects, training and capacity building activities, research publication recognition etc. It will be essential that researchers in the global north 'pay their way' and contribute appropriately to the maintenance of the service.
It should be expected that project grant funding would be drawn on to support further developments and enhancements. It is optimal, however, to design a business model that ensure core service provision is maintained by consistent funding and is not fundamentally dependent on short term, 'soft money'.
Data Access and Sharing Agreements
The INDEPTH network showed the value of sharing data across independent research sites, and this has been expanded by the ALPHA network. Through sharing aggregate data comparisons can be made across sites, and across countries. This allows a host of other aspects to be shared, including the best practice for management of data, and identification of gaps in the data. This project will take that further by introducing best practice for meta data development, and enabling the metadata to be searched across the internet. Findability is the key to scientific success and enabling sites to be found, encourages new partners to partner with in build stronger research.
The individual data from ALPHA and from the HDSS sites does need to be shared with care. While individual ID are removed, and artificial ID used in the ALPHA data specs, care needs to be taken to avoid unintentional identifcation of people and communities. For this reason, data sharing is by request, and for specific research questions only. A stronger data hub with dedicated professionals to manage the data will enable more data to be shared and for quicker agreement with potential partners in research.
Training
African data scientists face a number of constraints to their work. Open source software is needed because funds are not available for bespoke applications. However these open source programs require training to get the most out of them. Sharing of resources and networking of peers enables groups of professionals to tackle more complex problems and to build confidence and skills.
4: Conclusions and Broader lessons
- A model for research networks across Africa.
- A model for data exchange and integration.
- A model for discovery of metadata for data that has controlled access.
What is the relationship between the standards - DDI representation can be pushed into DCAT.
Recommend: that Alpha+ uses DCAT for collection level metadata.
Recommend: that Alpha+ uses DDI to capture collection, management and processes stages to provide provenance information in DDI and Prov-O. Document process.
Recommend: that Alpha+ expresses its information model in a generic way using ...
Data model for events and episodes allows combination with other data sets.
Combination of data collection techniques: paper, tablets, electronic medical records.
The unit is a person-variable reference-value. Arche type data. Person ID - variable type - value.
Data extraction using pentaho is semi-automated. Alpha boxes linked to London School via secure VPN.
Can we put the collection of the data / metadata into a hub in Africa?
Expose information models: residency model, etc. Allows users to identify if they are able to use it.
CIB - Centre in a box. DSS data is extracted into this. VPN network allows data to be transferred into London School.
New proposal has:
- DSS centres extract into the CIBs data relating to NCDs and CDs other than HIV.
- Transfer data to an Africa based hub.
- Africa based hub exposes metadata and has access control arrangements.
What is the ontology used?
Ontology needs to encompass:
Person ID
NCD or CD (disease categories)
Events (event types)