/
Dataset Catalog Vocabulary (DCAT)
Dataset Catalog Vocabulary (DCAT)
- Joachim Wackerow
- Simon Cox
Owned by Joachim Wackerow
Last updated: Sept 22, 2019 by Simon Cox
Presentation, document
What is DCAT?
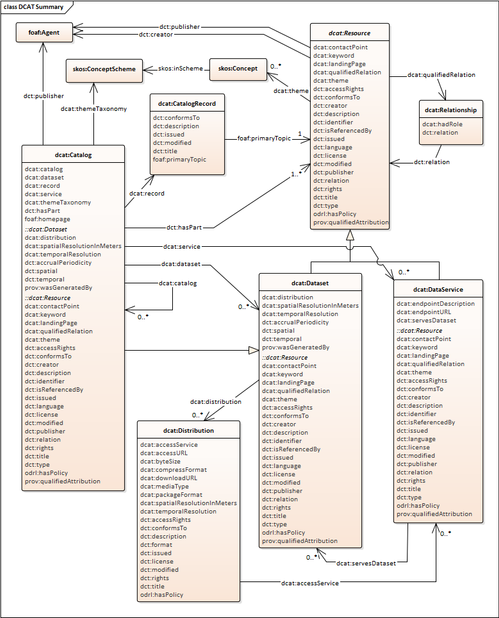
The W3C Dataset Catalog vocabulary (DCAT) is designed to facilitate interoperability between data catalogs published on the Web. It is based on a generic model for catalog contents including
- record
- description of (conceptual) entity
- related concrete artefacts
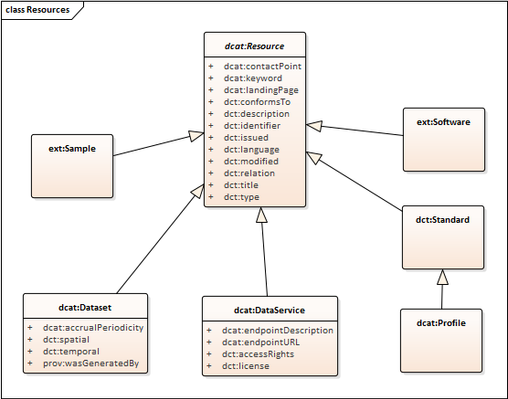
DCAT includes properties from the well known Dublin Core metadata element set, which are associated with classes for
(Original 2014 edition of DCAT)
- Catalog - a set of dataset descriptions and associated catalog records
- Record - the registration information for an item in the catalog
- Dataset - the description of a dataset, considered as a conceptual entity
- Distribution - the description of an actual representation of a dataset, e.g. a file using a specified format
since a Dataset may be available in more than one format or representation, there is in general a 1:N relationship between Dataset and Distribution
(Upcoming 2019 extension of DCAT)
- DataService - the description of a facility for discovery, access or processing data or related resources
- and sub-classes DataDistributionService and DiscoveryService
- catalogued Resource
- superclass of Dataset, DataService, and potentially other things that need cataloguing
Where is it used?
Europe - various APs, incl GeoDCAT-AP
CKAN add-on
Implementation
DCAT is formalised as an RDF vocabulary.
- dcat: Classes + skos:Concept/ConceptScheme + foaf:Agent
- properties from dct, dcat
- new classes for Services
- new properties from PROV-O, DQV
Mix and match with any (compatible) RDF
- ORG
- SSN/SOSA
- QB
- VoID
, multiple selections available,
Related content
Data Description
Data Description
More like this
Glossary work
Glossary work
More like this
2024 Evaluating and Refining Cross-Domain Metadata Exchange Frameworks
2024 Evaluating and Refining Cross-Domain Metadata Exchange Frameworks
More like this
Presentations 2024 Evaluating and Refining Cross-Domain Metadata Exchange Frameworks
Presentations 2024 Evaluating and Refining Cross-Domain Metadata Exchange Frameworks
More like this
Glossary Working Group
Glossary Working Group
More like this
2024 Aligning Technology Architectures with Cross-Domain Metadata Models
2024 Aligning Technology Architectures with Cross-Domain Metadata Models
More like this