ISO 19115 Geographic Information -- Metadata
- Simon Cox
- Stephen Richard
ISO 19115-1:2014 Geographic information -- Metadata -- Part 1: Fundamentals
ISO 19115-2 Geographic information -- Metadata -- Part 2: Extensions for acquisition and processing
A guide to ISO19115-1 is at http://wiki.esipfed.org/index.php/Category:ISO_Explorer. This is a set of html pages with some scope notes (usually pretty terse...) on all the model elements and attributes.
A Guide to ISO 19115-1
Stephen M. Richard September 18, 2018
Introduction
This document is an attempt to summarize the major content and intention of the metadata model developed by ISO Technical Committee 211 Geographic information/Geomatics. The discussion is by no means comprehensive, and is subjective, based on my experience using the spec and working on the ISO 19115-3 xml implementation.
ISO 19115-1 is a conceptual model intended for the description/documentation of resources that can have geographic extents, but the model defines information content for general-purpose metadata that can be used to describe resources that do not have geographic extent as well. The scope includes all types of information resources, including textual documents, initiatives, software, non-geographic information, product specifications and repositories. More detailed models for some aspects of resource description, including quality, data-structure, and imagery, are defined in other ISO geographic information standards.
The most widely used version of the standard is ISO19115(2006), via its XML implementation, which is specified by ISO19139. Typically when someone reports that they are using ISO19115, what they mean is they are encoding metadata information in XML according to the ISO19139 specification. Although adoption of the latest version of the specification, ISO19115-1 and its XML implementation (ISO19115-3), is not widespread, the improvements in 19115-1 are important for the purposes of this discussion, and the descriptions are based on that to be forward-looking. Some differences with ISO19115(2006) are mentioned.
Design use cases include:
- Enable information resource providers to effectively and completely characterize their resources.
- Facilitate the organization and management of metadata for information resources.
- Enable appropriate use of information resources through an accurate understanding of their characteristics.
- Facilitate resource discovery, access, retrieval and reuse.
- Enable users to determine whether an information resource will be of use to them.
The conceptual model is represented using the Unified Modeling Language (UML) graphical notation. The model includes 18 UML packages. These are broadly grouped according to their relevant topic area for discussion here, but this grouping does not necessarily coincide with the packaging in the model. There are a number of utility components that are used in various places throughout the model, and these are discussed in a following section. Finally, there is a section discussing some utilization challenges.
The 19115-3 XML implementation modularizes the implementation into 25 separate XML namespaces, and minimizes the dependencies between the namespaces. The design intention is to make it simpler to use parts of the model without having to import the whole thing, and to allow independent management of the model components. This implementation is starting to be adopted, but is not yet in wide use; the jury is still out on the success/utility of the modularized implementation.
Major metadata topics
This section discusses the main topic areas that can be included in ISO metadata documents. These topics are metadata about the metadata, basic resource documentation, constraints, content structure and function, distribution, lineage (provenance), usage, maintenance, related resources and data quality.
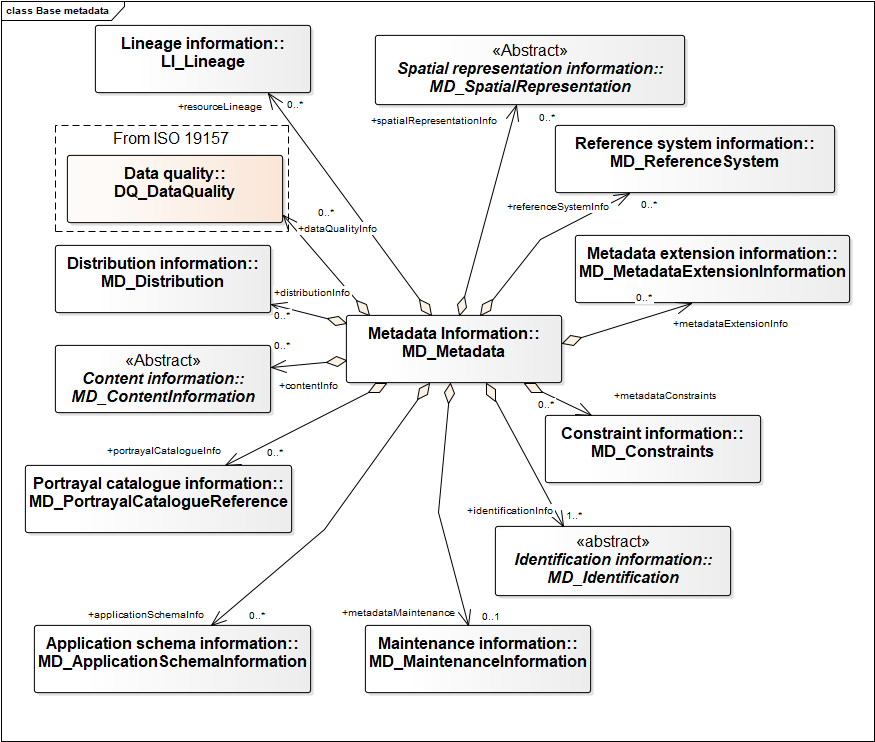
Metadata about the metadata
Each metadata record includes information about the origin, update date, creator, and maintenance of the record
- Identifier for the metadata record (as distinct from the identifier for the described resource).
- Language localization for the metadata content.
- Specification of the person or persons responsible for the metadata content (see discussion of responsible party in the components section, below);
- Dates for metadata creation and update,
- Specification of the metadata standard and profile that the content of the record conforms to
- Citation to a parent metadata record, to enable construction of hierarchical
- A URL that locates the metadata record online.
- Reference(s) to the metadata content encoded using a different standard (e.g. CSDGM, DataCite, other ISO profiles…).
- Information about maintenance of the metadata record, e.g. update frequency, descriptions of maintenance activities, contact information for the maintainer.
Basic resource documentation
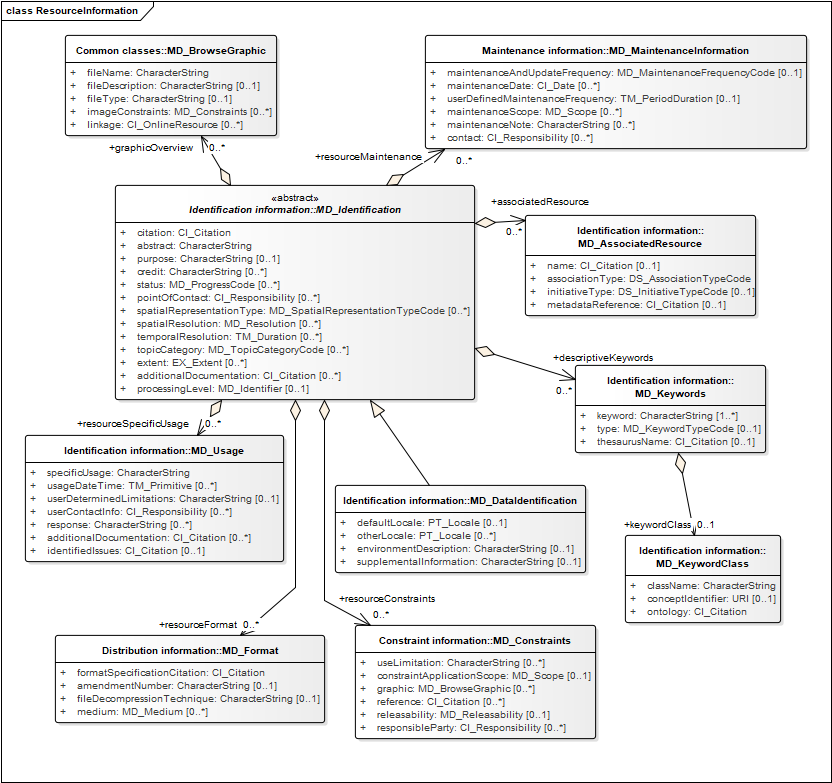
Information about the resource, including citation information (title, author etc.), identifiers, an abstract and various other free text descriptive fields, language of content, processing level, status,
- Citation element includes
- Title; free text, also has field for multiple alternate titles (e.g. different languages)
- Author, represented as 'citedResponsibleParty' (see the Responsible party description in the components section, below). Various parties can be associated with the resource in different roles specified from a controlled vocabulary, e.g. author, originator, principle investigator, publisher, co-author, editor.
- Publication date, one or more dates can be associated with the resource with different date type significance specified from a controlled vocabulary, e.g. creation, publication, revision, released.
- Identifier: URI(s) that are mapped to the described resource. Also includes specific fields for ISBN and ISSN.
- Presentation form (media), populated by controlled vocabulary, terms like documentDigital, imageDigital, mapHardcopy, tableDigital.
- Edition, series, other citation details (free text)
- URLs for the resource (see 'Resource Access links' in the Challenges section below)
- Language locale: documentation of language(s) of resource content.
- Resource type: categorization of the kind of artefact described by the metadata record is specified by a controlled vocabulary, or a free text 'scope name'. See Resource categorization in the challenges section below.
- Data processing level: specified by an identifier, intended to reference some standard categorization scheme, usually the producers coding system e.g. NOAA level 1B .
- Status: controlled vocabulary to characterize the progress state in development workflow for the resource. Example terms-completed, planned, final, pending, superseded, retired, accepted…
- Abstract; free text with information about the resource.
- Purpose: free text documentation of the intention for resource creation,
- Credit: free text acknowledgement of contributions to resource creations,
- Operational environment: free text description of the producer's processing environment, including items such as the software, the computer operating system, file name, and the dataset size.
- Supplemental information. Free text, other useful information about the resource.
- Links or references can be provided to additional documentation.
- Links can be provided to browse graphics that can be presented to users for quick visual evaluation of the resource if appropriate.
Keywords
The ISO 19115-1 specification defines a high level categorization based on subject area, with controlled vocabulary including values like farming, environment, geoscientificInformation, health… This vocabulary is used to populate a special keyword field named 'topicCategory'.
Other keywords can be grouped, with grouping defined by the 'keyword type', specified from a controlled vocabulary, by membership in a thesaurus specified by a citation, or by associating with a keyword class (in ISO19115-1) that can have a URI and a citation to a containing ontology. The grouping is optional; keyword can be specified by simply providing a list of word. The Keyword type or thesaurus groups are commonly used to guide construction of facets in search interfaces. By using the 'Anchor' element substitution for the generic CharacterString data type, a URI can be associated with individual keyword terms, but this approach is not universal and can break the xml parsing in client applications.
Identifiers
Identifiers are objects that carries several properties, including
- identifier string ('code'),
- namespace ('codespace') that might be versioned,
- naming authority citation that specifies the agent maintaining the namespace,
- free text description of the meaning of the identifier instance.
There is some ambiguity about what part of a URI should be in the codespace and what part should be the code; normal practice seems to be to put the entire URI string in the code. Although there is no explicit guidance, one common application of the description is to provide a human-intelligible label for opaque identifiers to use in user interfaces.
Geospatial aspects
Because ISO19115 originated in a community that was specifically interested in spatial data (especially data acquired by remote sensing) a key content area is documentation of the location relative to the Earth (geospatial location) that the information in a resource is about, and how the information in the resource content is mapped to location relative to the Earth.
Extent objects can include one or more geographic, vertical or temporal elements. Geographic elements can be a bounding box specified by two corner point coordinates using a standard spatial reference system (WGS84 latitude and longitude), a generic GML geometry, or an identifier object. Vertical elements have a lower an upper bounding value, and an optional specified reference system. Temporal elements can be specified by a time ordinal era (e.g. Jurassic, or Reign of Henry VIII), a calendar date and time, or a time interval specified by a begin and end calendar date time. The model allows spatial and temporal extents to be documented independently, or coupled as a spatial-temporal extent for subject regions that are in different geospatial locations at different times, or has one or more sampling extents that were sampled at different (possibly multiple) times.
Spatial extent
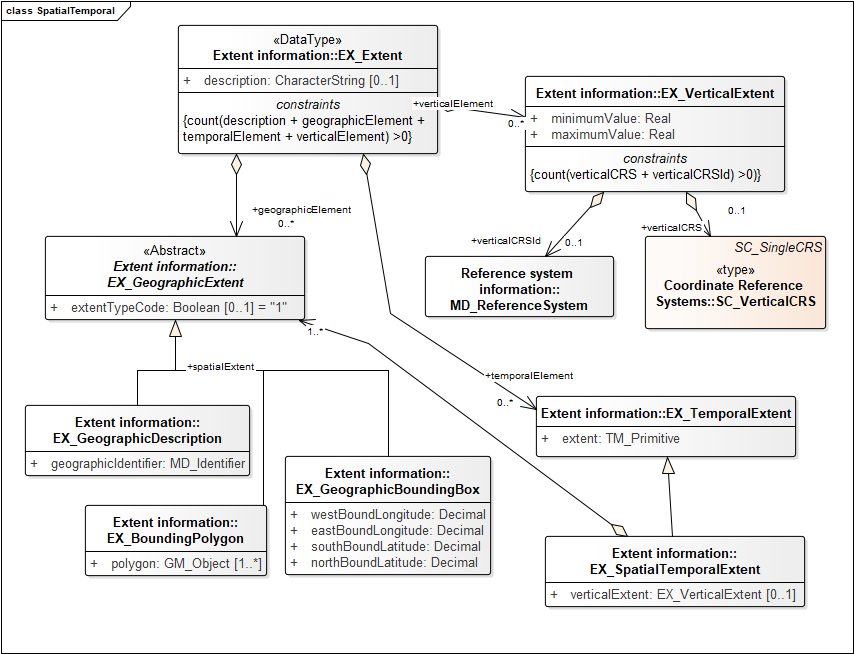
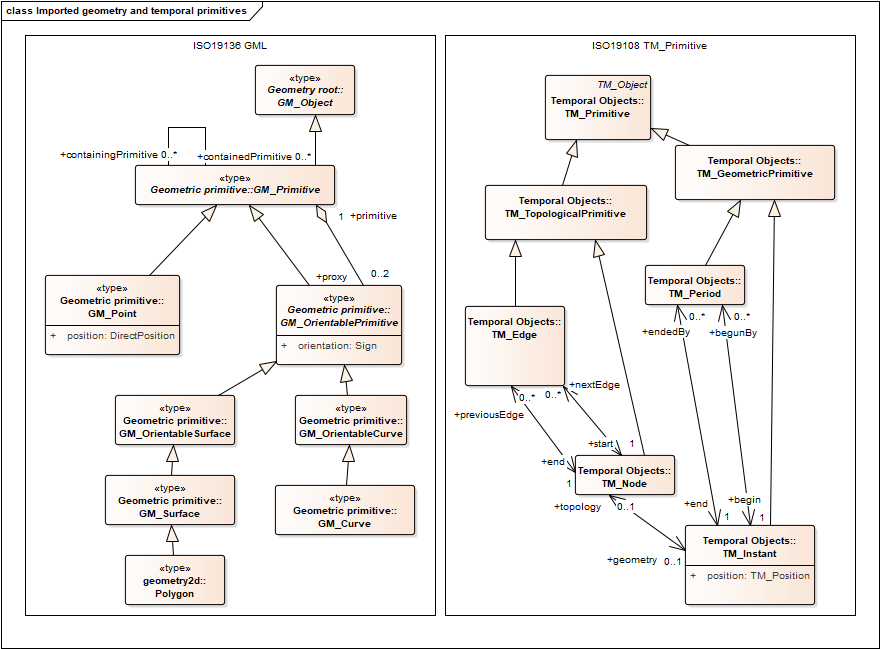
Spatial representation
This section provides elements to document how the mapping between data and location is implemented in the dataset. It accounts for vector representations, grids, and georeferenced images.
Spatial Reference System
This section provides elements to document how numeric coordinate values are registered to Earth positions, accounting for datum and map projection.
Spatial resolution
Documentation of the smallest distance between locations that can be distinguished in the spatial data.
Portrayal catalog
This section provides a citation to a separate document that provides a description of how spatial data can be visualized, assigning e.g. colors to polygons that have particular attribute values, or defining color ramps to use for visualizing image data.
Temporal aspects
These are properties for documented the time interval during which the data were collected or to which the data are considered relevant. For some thematic domains, e.g. geology, history, or archeology, this might be some time in the past.
Temporal extent
The ISO19115-1 model uses the temporal model from another ISO standard (19108), and allows a variety of options for represent temporal extent. The basic concepts are time instants and time intervals. The bounds of intervals are instants. The temporal position of an instant can be a time coordinate (defined in some temporal reference system), a calendar date time (defined in some calendar system), or a named time ordinal era from an ordinal reference system. There are obviously a lot of details that must be considered, see OWL time for a good reading starting point. The most commonly used implementation is an ISO 8601 date or datetime, or time interval bounded by ISO8601 date or datetime.
Temporal resolution
This is the smallest interval of time that can be distinguished in the temporal fields in the dataset.
Usage, security and legal constraints
Documentation for limitations on use, distribution, reproduction, etc are represented as access or use constraints categorized by a controlled vocabulary with values like copyright, patent, license, private, unrestricted…, or as security constraints categorized by a controlled vocabulary with values like unclassified, restricted, confidential, secret, protected…. Security constraints Any of these constraints can be accompanied by a text statement, and scoped to a specific part of the described resource ('constraintApplicationScope'), or to specific parties ('releasability'). Applicable licenses are specified using citations.
Resource Content/function
The original ISO19115 specification was strongly oriented towards image or raster based remote sensing data, and the Content Information section included in the model reflects that interest. Documentation of entity and attribute information is sometimes mapped into the content information section, but the intentions of the committees designing the specifications was that description of relational or object oriented data structures would use a separate specification, ISO19110 'Feature Catalogue'. Unfortunately, there was not a normative XML schema to implement the ISO19110 conceptual model until recently (after the release of ISO19115-1), making its use ad hoc.
Content information
Provides elements to describe a dataset represented as a coverage—a set of attributes on one or more variable dimensions; this approach is based on documenting gridded datasets like remote sensing data acquired from a satellite. The diagram below shows the content information elements implemented in ISO19115-3, which includes ISO19115-1 and ISO19115-2 elements.
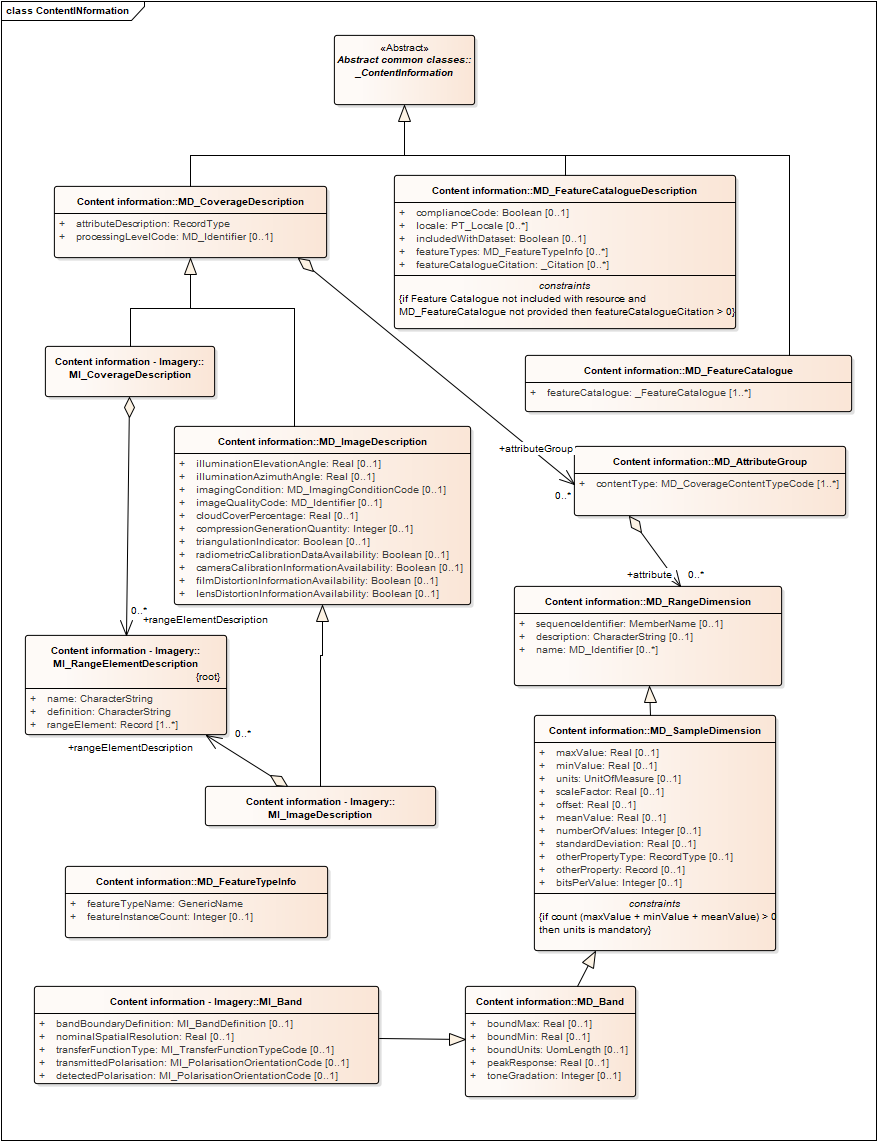
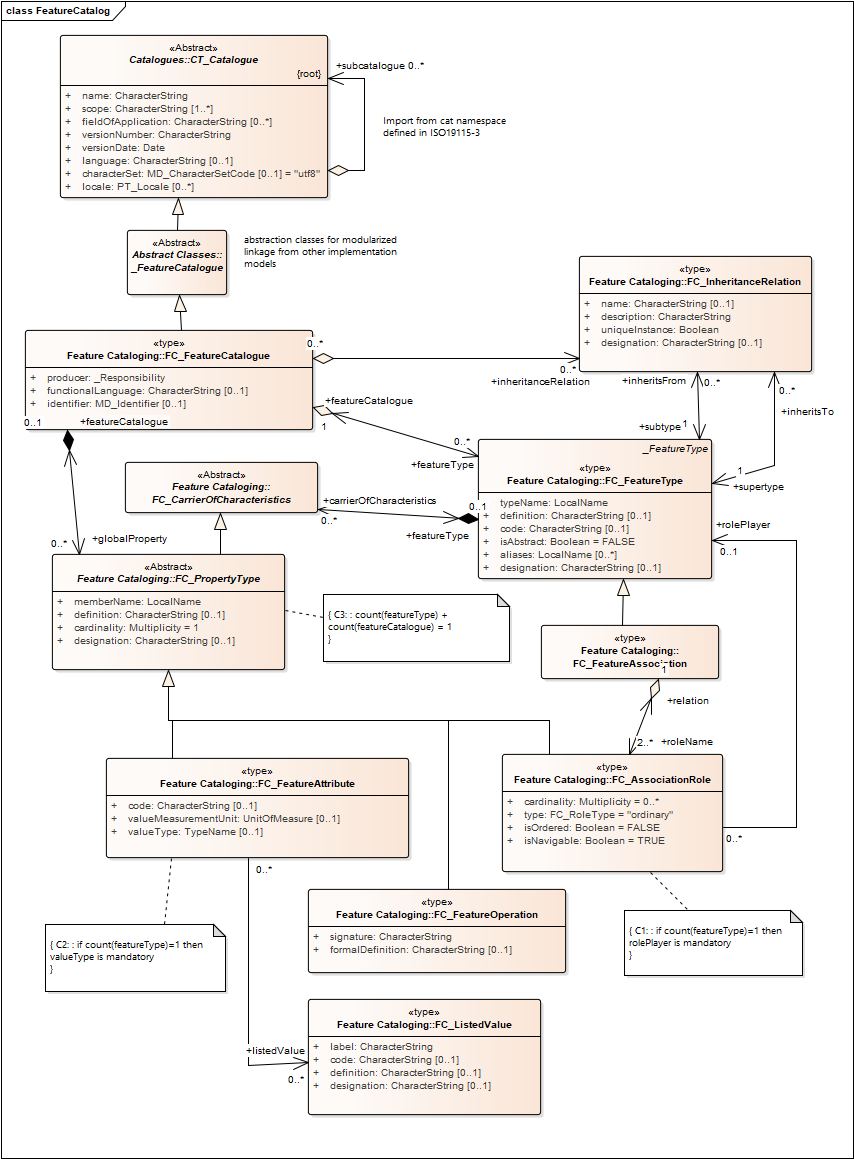
Feature catalog
A feature catalog(ue) (ISO19110) represents datasets as a collection of 'features', each of which has one or more attributes. This approach maps nicely to entity/attribute data structures typical of relational databases, or to object-oriented data structures. The UML diagram below shows the feature catalogue model from ISO19110.
Application schema
The ISO 19115-3 implementation allows a citation to one or more documents describing the application schema for the resource. The scope note for Application Schema link object (MD_ApplicationSchema) reads "the application schema used to define and expose the structure of a resource, i.e. the model and/or data dictionary that represents the resource.", which can be interpreted as a document that describes a data structure or the operation of an application. In practice this element is rarely used in my experience. The application schema element is a property of the base MD_Metadata element; multiple values are allowed, but the model does not include a binding between and application scheme and a particular distribution.
Services
The service metadata (SV_ServiceIdentification) section is also used in some profiles to document service interfaces implemented to access one or more datasets. There is opportunity for ambiguity and confusion here as to whether the metadata record is about a service as a set of operations accessible via some invocation process, or whether the metadata record is about a dataset and the service provides one means of accessing the dataset (which seems to be the more common situation). The USGIN and INSPIRE metadata profiles recommend using MD_DistributionInformation for service distributions of a specific dataset in metadata records that are about that dataset.
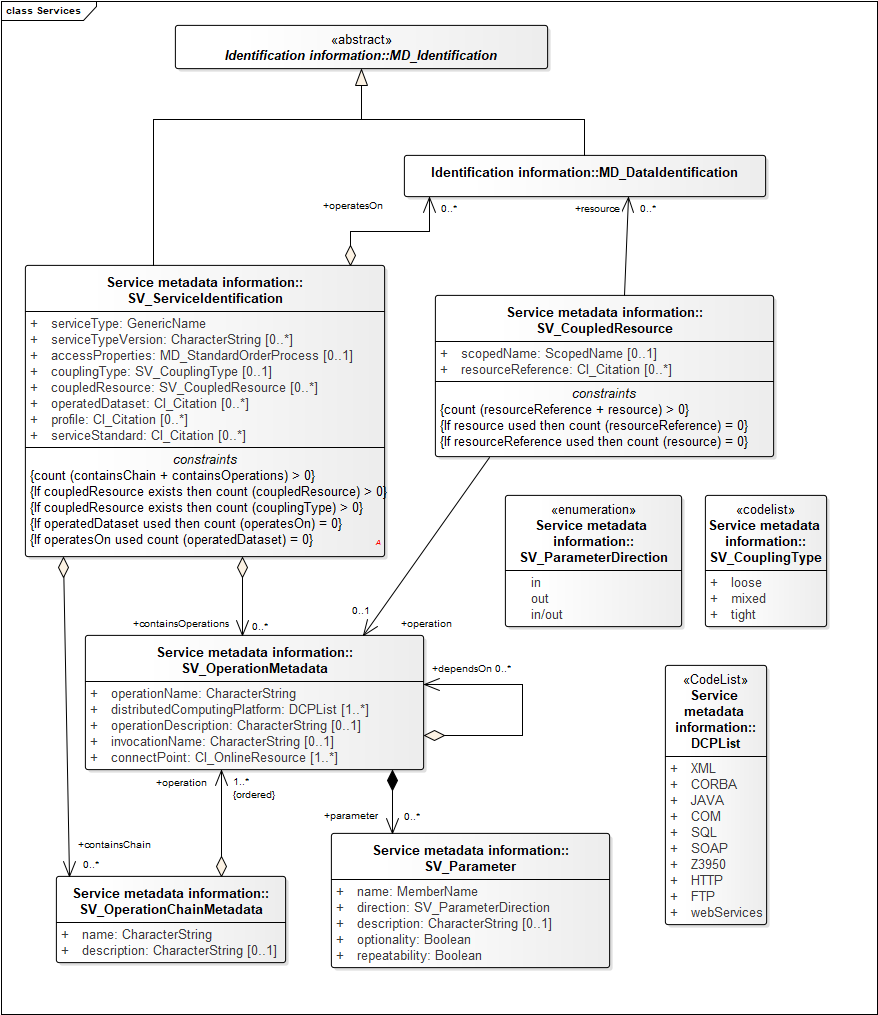
Resource Distribution
Distribution section provides information on how to access a digital representation of the resource described by the metadata record. The ISO19115 model is structured to allow multiple distributions, with multiple distributors, formats, and transfer options associated with each distribution. Transfer options and formats can be bound to a particular distributor or not. The model is quite flexible, but this leads to multiple approaches to documenting distributions, see Resource Access links in the Challenges section, below.
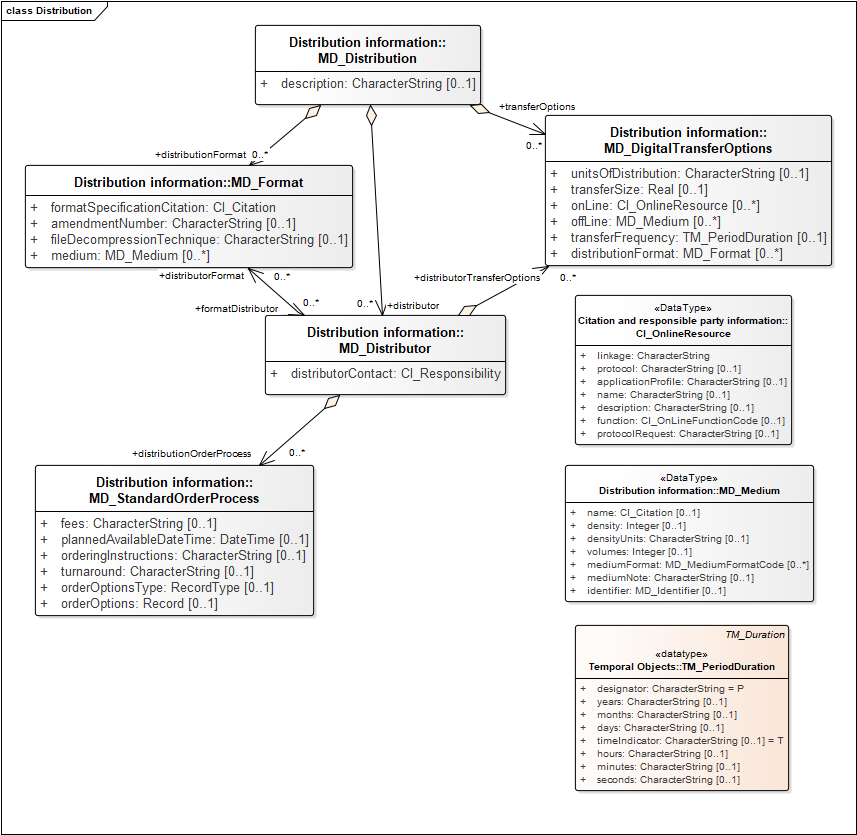
Distributor
Identifies a party responsible for maintaining a distribution process via a CI_ResponsibleParty component (see Responsible party in the Components section, below), and information about any ordering process associated with the distributor, including fees, available date, instructions, expected processing turnaround time, and an extension point for specifying any other applicable options
Format
Provides a citation to a format specification, information about the physical medium used for distribution, and a free text specification of any file compression used.
Transfer options
Documentation for a particular access option, typically characterized by a specific linkage (URL), but might also document details of an offline distribution. Optional properties include the unit of distribution (free text), transfer size (real number), formats accessible at the URL (not in ISO19115(2006)), and the rate of occurrence of distribution. Multiple URLs and formats can be associated with each option. Properties that can be associated with each linkage (URL) are
- Name – a label used to present the link in user interfaces.
- Description – text describing what the link does
- Protocol – online message protocol to be used. Documentation provides examples http, ftp, file, http GET KVP, http POST.
- Application profile – free text specification of an application profile associated with the link.
- Function – controlled vocabulary to specify the function invoked by the link
- Protocol request (new in 19115-1). Documentation is unclear; free text to provide example http POST request content.
Technically, the linkage is not required to be a URL (http URI), but could be any locator string with a known dereferencing mechanism.
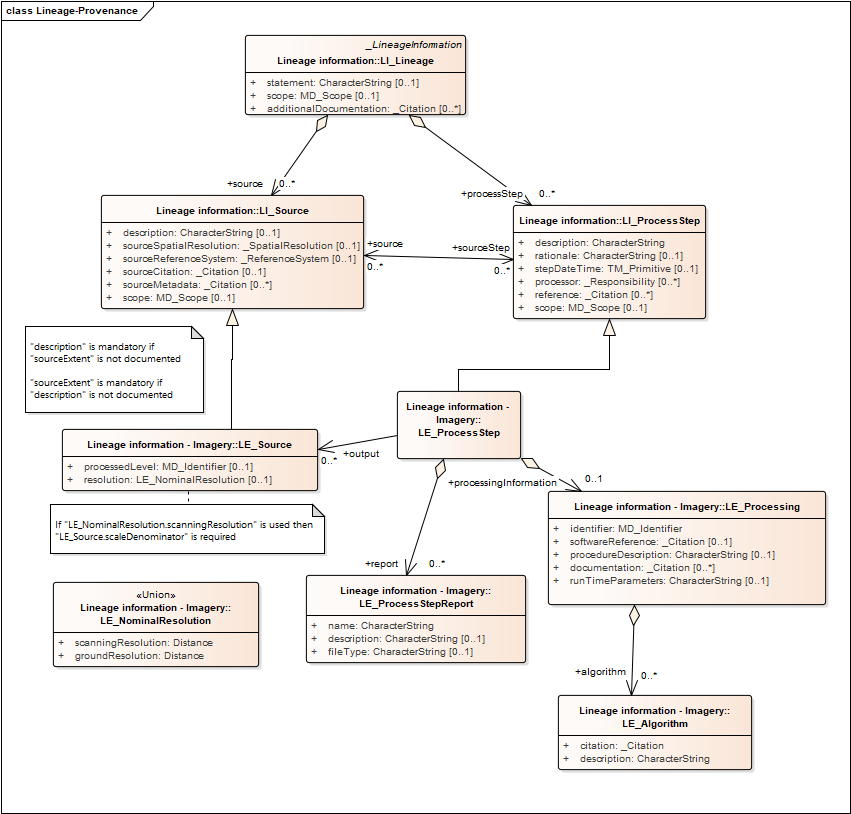
Lineage
Resource provenance is recorded by a collection of processing steps, each of which can have one or more associated sources (inputs), responsible parties, citations for related resources, a time stamp, a scope (resource part, space or time), and a description and rationale free text. Process steps can be ordered sequentially using the time stamps. ISO19115-2 adds additional elements; these are all implemented in ISO19115-3 XML, and are shown in the UML diagram below.
Usage
A collection of reports on usage of the resource can be included in a metadata record. These usage reports can include a time stamp, a responsible party for the usage report, various text fields documenting the usage, and links to citations with related information. The Usage element is shown in the UML diagram in the Basic Resource Documentation section, above.
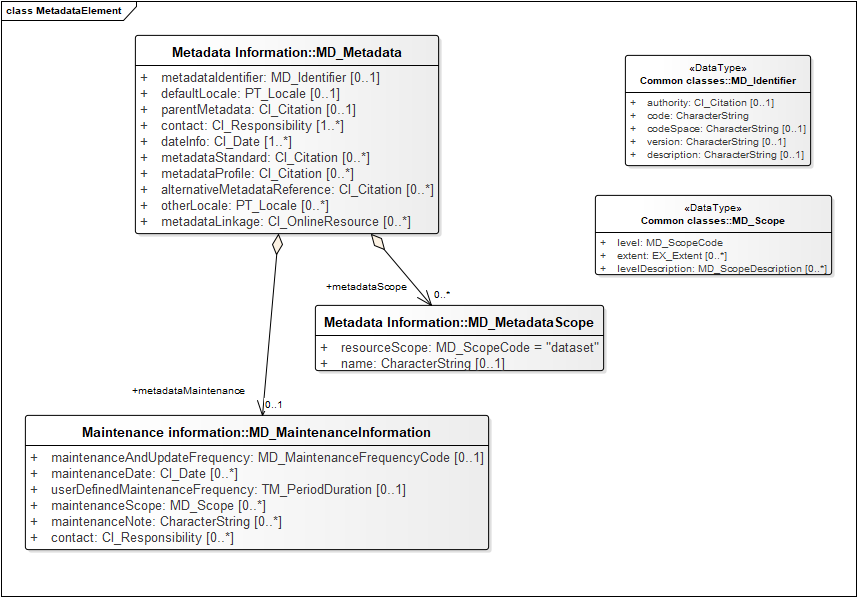
Maintenance
A collection of reports about maintenance of the metadata record or the described resource can be included, each with documentation about the frequency of updates, data of last maintenance, scope of maintenance, responsible party for maintenance, and a text description of the maintenance activity. The Maintenance element is shown in the UML diagram in the Basic Resource Documentation section, above.
Related resources
Related resources are linked via a citation to a metadata record for the linked resource, or a citation to the linked resource itself. Each related resource instance has an association type from a controlled vocabulary with values like crossReference, source, largerWorkCitation, dependency, isComposedOf. An optional initiative type can be specified, with values from a controlled vocabulary that includes terms like campaign, collection, exercise, mission, sensor, platform, program, study, trial. Based on the values in this vocabulary, the initiative type can be used to categorize the kind of linked resource. The AssociatedResource element is shown in the UML diagram in the Basic Resource Documentation section, above. Note that in ISO19115(2006) this element is named MD_AggregateInformation.
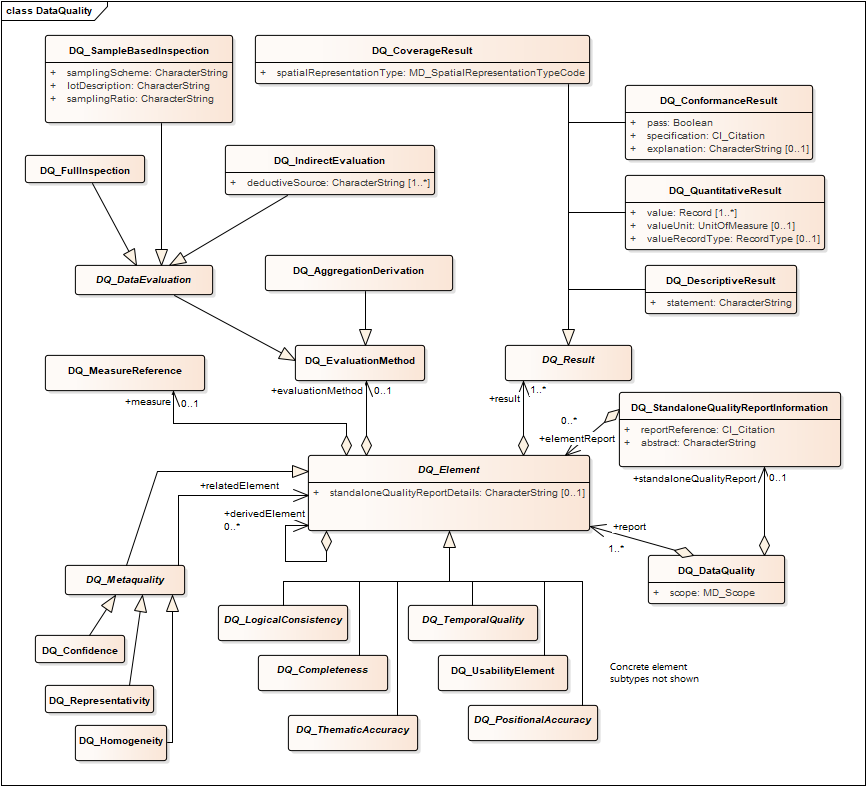
Data Quality
Data Quality characterization was included in the 19115(2006) model, but in the 19115-1 model, the data quality section has been moved to a separate ISO specification ISO19157. The model for documenting data quality is very similar in both cases, with only minor modifications and additions in ISO19157. The data quality documentation consists of a set of reports. The reports are hard typed, with 16 types defined, as well as a stand alone quality report option that is a citation to an external document. The report types are grouped in the following way: Usability, logical consistency, temporal quality, thematic accuracy, and completeness. Each report includes one or more result values that can be a simple 'pass/no pass', a quantitative value, a coverage (ISO19157 amendment 1), or descriptive text; result values can have a time stamp and a scope. Optional properties include specification of the evaluation method, an identifier and name for the measurement made, and elements to characterize the confidence, representativity, and homogeneity of the reported quality.
Components:
There are several data objects that are used as the value type for elements in multiple parts of the model, and in some cases could also be used in multiple metadata records. Instances of these could be stored in a registry and referenced from multiple metadata records to improve efficiency and simplify maintenance of commonly used information.
Responsible party
CI_Party represents individuals (name or role) or organizations, and affiliations between individuals and organizations. A party is bound to a role in various 'responsibilities' relative to a described resource. This allows the same person or organization be play multiple roles like author, maintainer, publisher, owner, distributor, editor etc. (CI_RoleCode vocabulary). Contact information including telephone number, postal address, and e-mail address are linked to parties. ISO19115-1 Amendment 1 adds an identifier property for each party so that URI's can be associated with people and organizations. It also adds an extent (spatial or temporal) property on a responsibility assignment that can be used, for instance, to document areas that were mapped by different people in a geologic map dataset.
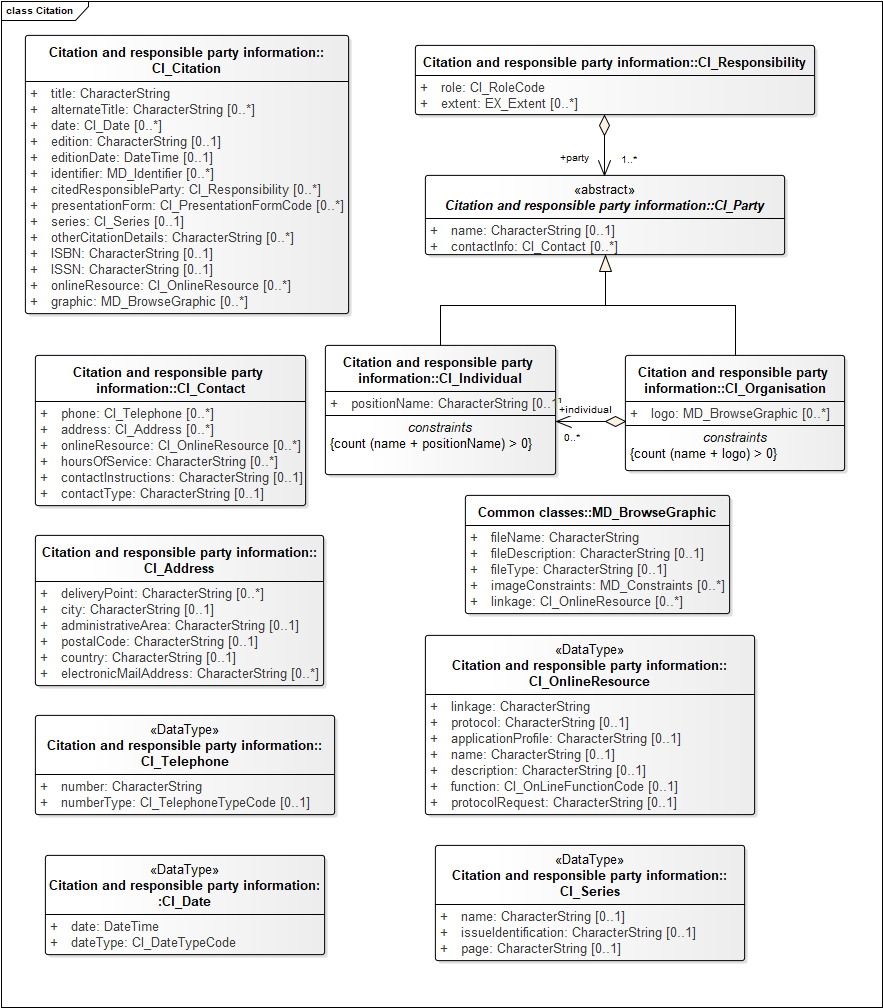
Responsible party is used in various contexts; various roles might be assigned to the party in any given context.
- Metadata point of contact
- Resource point of contact
- Cited responsible party
- Distribution contact
- Usage documentation
- Maintenance contact
Processing Step
Processing step descriptions (see Lineage, above) could be reused across multiple lineage descriptions. Verbatim reuse would preclude using the step time stamp to order steps in a particular process instance.
Citation
Citations are used in two roles:
- to provide the standard bibliographic citation content for the described resource
- to provide links or references to other resources in various roles, including additional documentation, sources that contributed data to create the resource, related resources, thesauri used for keyword vocabularies.
Citations in the second role might be used in multiple metadata records. The CI_Citation element is shown in the UML diagram with Responsible Party, above.
Extent
Named extent objects might be used in multiple metadata records.
Challenges:
The ISO metadata model is comprehensive and flexible at the cost of some interoperability problems introduced by allowing multiple approaches to representing the same information. There are a few concepts that are not well accounted for by the model as well. This section discusses a few of those issues.
xlink:href as Identifiers
The ISO xml implementation allows substitution of an 'anchor' element for any characterString value in an instance document. The anchor element adds the xlink attributes, which are not included in the characterString implementation. Some data providers use these xlinks to specify URIs corresponding to the provided string value, particularly for keywords, individual names, and organization names. This works well in the context of a community profile, but is not a general solution documented in the specification. ISO19115-1 fixes this problem for individual and organization.
Resource categorization
The 2006 version of ISO19115 categorized resources with a 'hierarchyLevel' property; in the 19115-1 version, this has become 'resourceScope', but both properties are populated by a controlled vocabulary with values like software, dataset, service, model, collection (the 19115-1 vocabulary has many useful additions over the original version). Both models also allow a free text label that is related to the resource type, 'hierarchyLevelName' in the case of 19115 (2006), or metadataScope/name in the case of 19115-1. For many purposes this resource categorization is too restrictive, and the use of the scope properties is inconsistent because of varying interpretation of the intention.
Related resources
Mix of hard typing (e.g. for Additional documentation or Browse graphic) and soft typing (MD_AssociatedResource/associationType) for linking to other resources. Semantics of associations are limited by a controlled vocabulary with values like crossReference, largerWorkCitation, source, dependency, revisionOf. Sources for resources that are aggregations (compilation, syntheses, reviews…) can be documented through links in the lineage (provenance) or as related resources. The URLs and URIs for linked resources are buried in nested citation elements.
Entity and attribute information
Content information, feature catalog (ISO19110), or application schema (a linked document) all are possible approaches to describing the structure of a described data set. The Content Information approach is probably the most widely used at this point because it was implemented in the ISO19139 XML implementation of ISO19115(2006)
Resource Access links
There are multiple options for documenting online linkage to a resource, including operation/ onlineResource, distribution/transferOption/onlineResource, distribution/distributor/ distributorTransferOption/onlineResource or identificationInformation/citation/onlineResource (note these are conceptual paths, not full xml xpaths).
Spatial Extent
Extent geometry can be represented as bounding box or generic GML geometry objects. Although the model allows multiple geometry elements, most client applications only index the first geometry provided. The bounding box is the most common method used, but has various problems. Many client applications have difficulty handling bounding boxes that cross the 180 degree E. longitude; although the box could be separated into multiple boxes if only the first bounding box provided is indexed, this does not produce the desired result. A dataset might contain information about widely separated sampling sites, e.g. hot springs in New Zealand and California, or ecologic observations in coastal areas of Virginia, Hawaii, and Tanzania. These lead to unrealistic bounding boxes and irrelevant spatial search results if a single bounding box is constructed to include all sites.
The use of the generalized geometry model from the Geography Markup Language allows representation of virtually any kind of coordinate-referenced geospatial location, with multiple points, lines, polygons, multi part geometries, polygons with holes, etc., but there are no search clients I know of that will parse complex geometries and use them for search.
These problems are not inherent in the ISO 19115-1 model, but rather in simplifications that are typically made in client applications accustomed to the simple one bounding box (or one centroid point…) approach.
File formats
Binding specific formats to specific distribution endpoints is not simple and there are not clear conventions on how to do it. The various places to document file formats (MD_format, distributorFormat, or distribution/MD_Format) lead to various interpretation and interoperability challenges.
Free text descriptive fields
There are various fields available for free text descriptive content, but the distinction of what should best go in these fields is interpreted differently. The descriptive free text fields include Abstract, purpose, environmentDescription, supplementalInformation, additionalDocumentation, otherCitationDetails. The benefit of have these various overlapping fields is not clear.
Identifiers in citations
The citation element includes a generic identifier field, as well as explicit fields for ISBN and ISSN identifiers.