Methodology Team Minutes
Wendy Thomas
Jay Greenfield (Unlicensed)
Steven McEachern (Unlicensed)
ATTENDEES: Jay and Dan
I had an interesting conversation with Dan Gillman the other day about the Methodology model that pertains to Workflows.
Basically I have been looking for a way to describe a Workflow "with some specificity" without having to go through the pain of Conditionally Sequencing a series of WorkflowSteps. Of course, my purpose was not to assist a software agent to execute a Workflow. Instead it was to give structure to the methodology section of a paper or thesis a human agent could use either to evaluate or replicate a result.
Dan characterized Methodology as a triple consisting of a Design, an Algorithm and a Process. To document a Methodology Dan indicated we might "use any one or two or all three elements in the triple.
He described an Algorithm as the "formalization" of a Design and a Process as the "instantiation" of an Algorithm.
Two use cases in connection with Methodology and the triple came to mind. In one use case knowledge was sufficiently advanced that there were several algorithms available and in use in connection with a methodology. Sort came to mind. In a second use case knowledge was not sufficiently advanced, there was no well known algorithm and we were forced into experimentation using ProcessSteps, ControlConstructs and the like.
Right now Workflows has a Workflow which "realizes" a Process. Otherwise it has a Design, an Algorithm and "contains" a WorkflowSequence. So, indeed, the Workflow class walks and talks like a Methodology. If Workflow were to "realize" a Methodology (instead of Process), we could short-circuit our use of Workflows and just describe its Workflow limiting ourselves to two elements of the methodology triple only: design and algorithm.
OK. So how do we express an algorithm? Wikipedia has thought about this a lot:
Algorithms can be expressed in many kinds of notation, including natural languages, pseudocode, flowcharts, drakon-charts, programming languages or control tables (processed by interpreters). Natural language expressions of algorithms tend to be verbose and ambiguous, and are rarely used for complex or technical algorithms. Pseudocode, flowcharts, drakon-charts and control tables are structured ways to express algorithms that avoid many of the ambiguities common in natural language statements. Programming languages are primarily intended for expressing algorithms in a form that can be executed by a computer, but are often used as a way to define or document algorithms.
There is a wide variety of representations possible and one can express a given Turing machine program as a sequence of machine tables (see more at finite state machine, state transition table and control table), as flowcharts and drakon-charts (see more at state diagram), or as a form of rudimentary machine code or assembly code called "sets of quadruples" (see more at Turing machine).
Representations of algorithms can be classed into three accepted levels of Turing machine description:
- High-level description
"...prose to describe an algorithm, ignoring the implementation details. At this level we do not need to mention how the machine manages its tape or head." - Implementation description
"...prose used to define the way the Turing machine uses its head and the way that it stores data on its tape. At this level we do not give details of states or transition function." - Formal description
Most detailed, "lowest level", gives the Turing machine's "state table".
Based on the thinking Wikipedia has done, for certain purposes we might use any of the three description levels above in place of a Process description using the Workflows package and the ProcessPattern it realizes apart from just one class -- Workflow -- which implements a Methodology.
In this instance Workflow would NOT be connected with WorkflowSequence and, as a consequence, it would NOT contain any WorkflowSteps. Instead, using one style of expression or another, these steps would be described in an Algorithm.
An algorithm is not "machine ready". This statement, however, deserves more attention. Consider the following:
Minsky: "But we will also maintain, with Turing . . . that any procedure which could "naturally" be called effective, can in fact be realized by a (simple) machine. Although this may seem extreme, the arguments . . . in its favor are hard to refute".
Gurevich: "...Turing's informal argument in favor of his thesis justifies a stronger thesis: every algorithm can be simulated by a Turing machine ... according to Savage [1987], an algorithm is a computational process defined by a Turing machine".
I would only dare to add that a Turing machine is more a heuristic device (an abstract machine through we learn about computers) and less an actual one. This is in line with Dan's view that an algorithm is in the final analysis NOT an implementation. Implementation is the domain of a Process.
By way of example consider "pseudocode". Pseudocode is not machine ready. Neither is natural language, flow charts or control tables. All require an "interpreter". That interpreter could be a machine but that machine would be the product of machine learning orchestrated by a human. Once more: none of these algorithms are machine ready. All require interpretation.
ATTENDEES: Larry, Jay, Michelle, Steve
- review and discussion of emails regarding workflow orders
View - need to get the workflow and process pattern correct.
Workflow classes for Qualitative, coding and segmentation
- concern regarding where we have abstract classes - we could have potentially a lot of classes
- Should we think about having some concrete generic classes that are extensible - so if semantic is wanted - we could extend it.
- are there issues with doing it this way?
- Example: Goal rather than a particular type of goal
- Abstract vs non-abstract - if abstract we need another layer - and cannot use directly
- for some patterns - make as concrete as we can?
- results is another -
- goal, results, are abstract - do we remember why?
- review of bindings - there is a concern that we may be out of sync
Quick DD and FHIR discussion
TODO:
- Dagstuhl - need a meeting of the Methodology group face-to-face to "sync"
Looking at Sampling Methodology, SamplingPreMethodologyPattern, Sampling Design Powerpoint, and SDI Sampling work
- There is a design is associated with a Process and somewhere in there is a sampling frame
- Can we fix sampling into the Methodology Pattern?
- It contains more of the sampling design than the act of sampling.
- Unclear as to how much the model provided explains the process - unclear what has been done
- The possible amount of detail being talked about seems to exceed the design
- The powerpoint is ONLY a design
- You'd need a specific design - you could have a design that called for 2 stages both using simple random sampling
- The algorithm is the random sample
- The data of the model Dan wrote is the data around the what rather than the how (design not process)
- Frames are inputs - they get invoked in the process
- Algorithms talk about the requirements of the frames
- Questions about the relationships between the Design and Algorithm - which comes first?
- Are we talking top down or bottom up
- Example: I want to sort something
- Do I need to version Design every time I add a new sorting algorithm?
- You probably wouldn't change the design because the point is to order a set in some way and that is the design
- The algorithm used to do it would be specified at the instance of some sort i.e. implementation of the sort process
- Probably need examples to answer this.
- Sampling seems more direct because there is more you need to nail down - many more specific things
- Should Algorithm be an inputoutput?
- The choice of algorithm is a conceptual input to creating the process rather than the implementation of the process where the output is the process.
- An Algorithm is an executable.
- Identify issues in the sampling methodology
- Identify issues for the model in general
- How do we see the MethodolgoyPattern of the model used
Need to write a document of:
- what the Methodology Pattern is
- how it is realize
- the scope of its coverage
- how it got here
The Wiki page needs to be updated to relay current thinking.
ATTENDEES: Dan G., Wendy, Jay, Larry, Michelle
Agenda / Minutes:
- Can we review the new MethodologyPattern (new)
- Wendy reviewed
- 4 classes in pattern - design, process, algorithm, methodology
- still links to process pattern
- a quick review of the Process Pattern
- Class Methodology - allows user to add an overview of the methodology - higher level overview
- Sampling example would contain the following classes within the Methodology Pattern:
- Sampling methodology - provide overview
- Sampling Algorithm
- Sampling Design
- Sampling Process ?
- Sampling example would contain the following classes within the Methodology Pattern:
Discussion regarding whether the pattern is the correct way to go - looking into the future. Dan does have reservations regarding the MethodologyPattern so the modeling perspective may not necessarily reflect future methodologies. Wendy will include a question with the Q2 release asking whether folks believe that the pattern is the best way to go for Methodology.
2. Consider dropping the Methodologies package in line with Flavio’s comment in the attachment
- Need to review the Process Package where
- Rationale ~ Input
- DDI Result ~ Output
- Tighter interweaving with the process pattern - may see future with them together
- When will this be done? This is the BIG question
- Discussion and review of the use of Rationale as a property in Design and Methodology. Do we need the DDI_Rationale? Is rationale in Methodology sufficient? Change made in Lion to reflect the discussion.
- Good practice to always have a Methodology class - this will need to be clearly documented for the user. A Design must always have a methodology - can we make this happen?
- Need to review the Process Package where
3. Consider Larry’s comment that some things missing in Lion packages that we should have: Specific methodologies derived from the Methodology pattern (e.g. sampling and weighting) (Michelle)
- need to review what is in the Codebook spreadsheet - sampling, weighting, data collection, data cleaning
4. Get an update from Larry on how we might use the MethodologyPattern in the StudyRelated package (new)
- has a design, process - but they are not connected in the StudyRelated package - and they need to be.
- If this happened then we can reuse?
Next Steps:
- Wendy will do the Realization of Sampling - will get back to us when it's complete for us to review. If we get Sampling ready - it will be included in the Q2 as a realization.
Next Meeting:
Sept 19, 2016 - I'll email to confirm
ATTENDEES: Larry, Flavio, Wendy, Jay, Michelle
- Quick review of Research model proposed by Jay and Dan from the Norway Sprint to decide whether we go with a Pattern or not.
- Decision was to go with the pattern
- There will be 4 classes:
- Methodology
- Design
- Algorithm
- Process
- This will allow users to create their own domain specific names for the classes when realizing their methodology
- This will require CLEAR documentation - especially when it comes down to the Process class
- Patterns are included in the Q2 release, which means this particular pattern may be released as well. Documentation will state that there are no implementations available with Q2 - for methodology
- That brings us to Codebook View - the methodology package will fit in nicely and we can identify some realized implementations
Next Steps:
- Wendy will make changes in Drupal
- Wendy will bring the pattern to the Modelling Group
- Larry and Michelle will take the Methodology package to the Codebook group to discuss what implementations should be developed
Follow-up:
A new package MethodologyPattern has been created and the following classes moved from Methodologies; Methodology, Design, Algorithm, and Process.
NOTE that these classes were made abstract AND had their extension base changed to Identifiable. This is part of an effort to streamline the contents of classes in Patterns as the realized class can always use the extension base AnnotatedIdentifiable.
Next Meeting:
August 22, 2016 -
Binghamton (USA - New York) Monday, August 22, 2016 at 3:00:00 PM EDT Canberra (Australia - Australian Capital Territory) Tuesday, August 23, 2016 at 5:00:00 AM AEST Berlin (Germany - Berlin) Monday, August 22, 2016 at 9:00:00 PM CEST Washington DC (USA - District of Columbia) Monday, August 22, 2016 at 3:00:00 PM EDT Detroit (USA - Michigan) Monday, August 22, 2016 at 3:00:00 PM EDT Minneapolis (USA - Minnesota) Monday, August 22, 2016 at 2:00:00 PM CDT
ATTENDEES: Larry, Steve, Flavio, Wendy, Michelle
- Review and discussion of the Research model proposed and developed by Jay and Dan at the Norway Sprint
- Discussed the merits of using a "pattern" for the upper left hand side of the proposed design
- Will recommend to modellers that this be treated as a pattern - recognize that it will be modellers design in the end.
- Need to work through realizations of pattern
- We will use the DDI-SRG listserv for communications and use the DDI-METH acronym to denote the Methodology team

Next Steps:
- Wendy will update Drupal with left hand side of the proposal
- Once complete - Michelle will create issue for the Modellers to review as a pattern
- Team needs to work through a few Realizations (examples)
Next Meeting:
July 25, 2016
ATTENDEES: Wendy, Jay, Michelle
- Quick overview of the last meeting (Michelle was not in attendance and no minutes were available)
- Jay worked on Model based on Dan's methodology model
- Jay will post updated PPT of the Methodology model based on Dan's model and discussed changes
- Next steps:
- Everyone review PPT
- Meet in 2 weeks - to review and discuss Methodology model
- Need to identify what pieces are abstract
- Required or rather HIGHLY PREFERRED attendance by:
- Jay
- Wendy
- Dan
- Larry
- Flavio
Michelle will contact team members to find a time that works best for everyone.
ATTENDEES: Wendy, Larry, Jay, Barry (first 10 minutes)
Methodology:
We talked about changes made to the Methodology Model during the Edmonton Sprint and what the implications were for instantiating the model either as is or as a pattern. If it is instantiated "as is" then it would need some additional samantics to indicate the type of Desgin/Algorithm/Process. If turned into a pattern which classes should be abstract and how would the pattern be realized by say the Sampling Method. Some points brought up in discussion:
- Should it be a pattern?
- How would that change how it looks?
- An algorithm is a design pattern that espresses a design and is implemented by a Process
- The design is the extension point for sampling, coding and things like that
- What the algorithm describes is the pattern people use and want to express in Codebook like Collection Method, Time Method, etc.
- How would you use the present model as an instantiated thing?
- Study level: experiment, survey, study design
- Time Method
- Sampling Method - high level algorithm / pattern
- This represents some family of solutions to sampling then the algorithm or design pattern would be abstract and it would then kinda of branch in to models for more specific things
- You'd have to bring in the process model to complete this
- Confidentiality Method
- If it was a pattern how would that change it and how would it be realized?
- What would be abstract? Design, Process, Algorithm might need to be extensible
- What does it gain you?
- Use the objects from 2.5 and see if we can provide that information in a more structutred way using the methodology model
- What we're seeing is what the pieces are and how the pieces are put together and use this approach with Codebook content to see how we could use different levels of content
ACTION: See how Sampling Method would look given the changes in the Methodology model. (Jay will play with this) It would be useful to have both an example of how to realize the Pattern/instantiate the model AND how this could be trimmed in view for various levels of information (general description, detailed processing, relaying information to the data user). There looks like there would be work here for the sprint in the context of the Codebook group and also some preparation work to allow Codebook group to explore possibilities for using the Methodology model effectively
ATTENDEES: Wendy, Larry, Dan G., Steve, Natalja
Regrets: Flavio, Barry, Michelle
AGENDA
Discussed documents sent out by Wendy (model and discussion)
{kind=link}
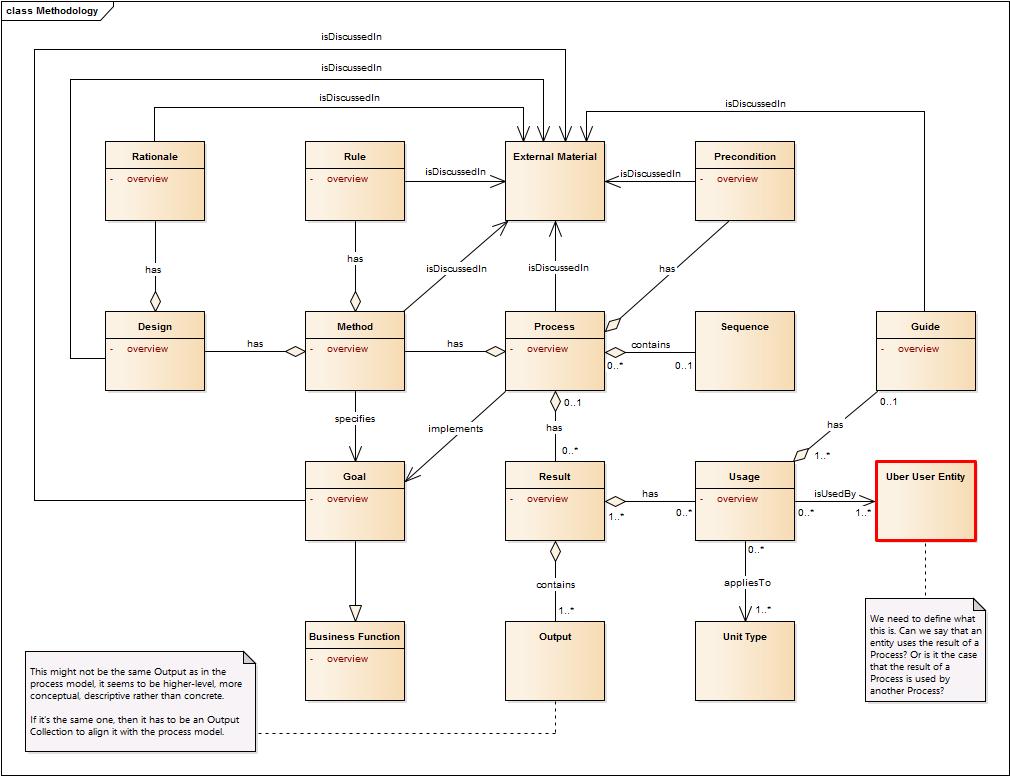
We started by looking at the changes resulting from making the link between Methodology and Core Process model clearer and Wendy's understanding or misunderstanding of the relationship between Method and Process and Method and Design
- Processes can be ad-hoc, not having a design or underlying method
- This is especially true if you are describing a process that has already taken place and you don't know the design information
- The Design is what the Process is intended to do
- There can be a theory behind the Design, where is this captured?
- Add an underlying theory to the design - if we are going to point to it from anywhere it should be from the design
What is a Method? Is it actually an Algorithm and if so where should it fit in the model?
- Process implements an algorithm but you infer the algorithm from the process
- Algorithm sits between the design and the process
- Design - what are we going to do
- Algorithm - says how we're going to do it Process - is the implementation
- If we're going to keep a box between Deign and Process then Algorithm should sit between and Process where Method is sitting in this diagram
- How to meld the process model to the methodology model
Further discussion of Algorithm
- Change Method to Algorythm (a Process derives from an Algorithm)
- Algorithm informs the design
- Method informs design (Steve) agggh (Dan G)
- Algorithm informs the design and the design articulates the process
- The Ruggles' method is prepresented by the Algorythm, my design implements the algorythm using this process
- I'm going to fit the following algorythms to accomplish something
- Don't forget Dan's point for not insisting on an algorithm or design
Where we got to:
- Design gets connection to the Rule and Goal and direct connection to Process (process implements designs)
- Design includes Algorythm (0..n)
- Algorithm can be external material - reference to an approach I'm adopting or could be just an idea
- Design and Method difference - Method is mislabeled and misplaced, Design should be next to Process
- Algorithm will be associated with Design (off to the side)
- Definitions:
- Rationale is why
- Goal is the desired outcome
For next week:
- Redo diagram with changes noted above (Wendy/Flavio)
- Provide a chain of the models dating back through time noting changes between each model (Wendy)
- Provide documentation of class definitions (Wendy)
- Review lower right section of model containing new classes as we didn't get to this (all)
Minutes for Methodology team meeting, 7 March, 2016
Attendees: Dan Gillman, Larry Hoyle, Steve McEachern, Barry Radler, Wendy Thomas, Michelle Edwards
- Wendy created Issue DMT #64 (
DMT-64
-
Getting issue details...
STATUS
) for the modellers to add an Overview for methodologies. This follows a discussion at TIC and the Methodology group
- The overview may be a paragraph or two to provide a high level "description" of the methodology
- Need to add a comment to request that Overview be added to DMT #61 ( DMT-61 - Getting issue details... STATUS )
- After reviewing and comparing the model in lion.ddialliance.org and the Ubermodel on the wiki - it was determined that they do not match. Wendy will review and update the model on lion.
Design models:
- Larry provided a preliminary overview of a Design model for Qualitative Analysis based on Richards, Lyn Handling Qualitative Data SAGE Publications Ltd (https://uk.sagepub.com/en-gb/eur/handling-qualitative-data/book241828)
- Steve and Barry will connect to start the conversation regarding a Design model for Editing data - this will also link to Data Description, Data Capture
Agenda for 21 March 2016:
- Design model updates
Minutes for Methodology team meeting, 8 February, 2016
Attendees: Larry Hoyle, Steve McEachern, Jay Greenfield, Dan Gillman, Michelle Edwards, Barry Radler
Regrets:
Dan's Coding Design
- Changes made last week were accepted
- Any further feedback on this Design should be forwarded to Dan and then passed on to the Methodology team
Codebook:
- Question: What do we need to do from the methodology perspective for the Codebook View?
- Generally, we are currently on the right track with the Uber Methodology Model and developing Design models to tackle different methodologies
- When thinking about the current Codebook, should there be a way to describe a higher level of methodology? We may not always want the details but just a general description of the method
- How do we do this? or can we do this?
- This should be done and available
- Discussion about different ways to deal with this
- Templates - these could be used to grow to different levels of specificity
- more detailed where required/wanted
- more general where needed (Codebook)
- develop a template based on what we have already and use new Designs as a test to determine whether our template works
- Remember that the primary challenge of codebook
- We need to think of it as a division between the needs of a data library/archive and the statistical agencies
- Research: What you plan to do vs what you actually did - with respect to methodologies
- Methodology Class?
- borrow from other standards:
- abstract
- plan
- executed
- We could work these out based on our Uber Methodology Model - something to consider
- Planned vs. executed
- borrow from other standards:
Tasks for next meeting (Monday, February 22, 2016):
- Think about how we could develop a template
- Discuss different approaches at the next meeting
Minutes for Methodology team meeting, 25 January, 2016
Minutes for Methodology team meeting, 11 January, 2016
Attendees: Larry Hoyle, Steve McEachern, Jay Greenfield, Dan Gillman, Michelle Edwards, Barry Radler
Regrets: Flavio Rizzolo, Marcel Hebing, Natalja Menold
- Dan G. gave us an overview of his Coding Design
- discussed possible updates/changes which included adding in Training Materials - which were most likely part of the Manual Operations
- do we look at GLBPM - breaking apart these tasks into smaller components and mapping to GLBPM
- Decision support system
- think of this as a flowchart to get people to use this
- Nesting models??
- Is this something that we need to look at?
Next meeting: 25 January 2016
Agenda:
- Review any changes to Dan's Coding Design
- What do we need to do for Codebook?
Minutes for Methodology team meeting, 8 December, 2015
Attendees: Larry Hoyle, Steve McEachern, Jay Greenfield, Dan Gillman, Michelle Edwards, Barry Radler
Regrets: Flavio Rizzolo, Marcel Hebing, Natalja Menold
- Follow-up on meeting times - these will be every 2nd Monday at 1300 Eastern time starting on 11 January, 2016
- Discussion:
Life Cycle and Methodology
- steps along the way
- has a design and a process
- application of a methodology
- think about microdata on the web - want to be able to organize it in a meaningful way and talk about the survey itself
- expanding for a much finer level of detail - want to nail everything down
- ability to document everything we do - need to work out all those pieces
Different designs to examine and volunteers:
- Steve: editing - ABS is interested in this as well. Justin may be interested here as well
- make metadata active
- Jay: Clinical trials
- Dan G: Coding - this was started in Minneapolis
- Larry: Qualitative analysis
Designs to investigate:
- Scientific experiments - Jay will start us here with the Clinical trials aspect
- Epidemiology - emulated clinical trials
- Data Integration - think of this as a result of creating a Consumer Price Index (Food Basket)
- Derivation? this probably falls more in the area of Data Description
- Data Mining - May be partly data derivation, but we could decide that this is different
- there are members of the DD group in Methodology - so lots of crossover and awareness
- Machine learning
Minutes for Methodology team meeting, 17 August 2015
Attendees: Larry Hoyle, Barry Radler, Wendy Thomas, Michelle Edwards
Regrets: Dan Gillman, Flavio Rizzolo, Marcel Hebing, Natalja Menold, Jay Greenfield, Anita Rocher, Steve McEachern
- Review meeting times. Those in attendance were in agreement with trying to find another day and time to meet. Michelle will send out a Doodle poll with proposed times, being cognizant of several DDI meetings being held on Wednesdays, and the wide range of home timezones of our participants.
- Upcoming Dagstuhl Sprint - please think about questions that we, as a group, would like to submit for review by the External participants at the Workshop. Either submit here, send to me directly. I will collate and submit on behalf of team to the DDI planning group.
- List of design models - is VERY sparse, please login to WIKI and add your list.
We did talk about the Terms of this group - there currently is a lack of clear direction and terms of reference for this working group. It's been around in different iterations for a while, but it is time to come up with a clear mission and goal for the group. Michelle will review all documentation available for this group and start a Terms document to circulate to the team for additions, deletions, etc
Michelle will also review documentation to create a doc that highlights what we have accomplished and where we are going - this would be great information for the upcoming Dagstuhl workshop. Will send around for additions, deletions, and comments.
Barry also talked about the Data Capture group and thought it should be a smaller "view" within this group. It fits between Data Description and Methodology.
Meeting adjourned
Minutes for Methodology team meeting, 22 July 2015
Attendees: Dan Gillman, Barry Radler, Anita Rocha, Jay Greenfield, Flavio Rizzola, Larry Hoyle, Wendy Thomas, Steve McEachern (joined in later), Michelle Edwards
Apologies: Marcel Hebing
This was our first meeting with Michelle as Chair. Primary goals of this meeting were to review document of proposed goals for this group and set out a work plan.
A quick review of the document linked here, lead to a brief discussion over the definition and what was meant by the term "design model". Examples that have been developed in the past include: sampling, questionnaire design, weighting, and paradata. The "design model" provides us with the basis to develop the models to be added to the Methodology Model.
The team agreed to contribute to alist posted here of design models they feel should be included in our work. Dan provided a great list as a starting point on the call. It was noted by Barry and supported by others that we need to think beyond survey designs. Larry reminded us that we also need to think about analysis designs. Our discussion continued regarding some of the design models we identified at the Minneapolis.
Linkage between Methodology team and Data Capture? This is still a question - relates to a larger question for the Moving Forward project.
Unsure whether methodology will be referring to the Process model - are we using is directly? There is a pattern here! The question should be is there a pattern of usage. How will people use the pattern or rather let us show you how to use this model for this particular case - Intersect point.
Tasks to keep the work going:
- Dan will continue work on the Coding model that began at Minneapolis.
- Wendy will start working on a model for Harmonization in September
- Flavio will look at the BPM model
- Jay will be looking at a proof of concept project using the Sampling model
Future tasks:
- Need to think about the Daghstuhl agenda - what do we want to see as a product from the Sprint?
Next meeting is set for August 5 at 6pm Eastern. We will review this meeting time in September - but for the next month we will maintain this time.
Minutes for Methodology team meeting, 17 June 2015
Attendees for the meeting: Michelle Edwards, Jay Greenfield, Steve McEachern, Michelle Edwards, Flavio Rizzolo, Larry Hoyle, Wendy Thomas
Apologies: Dan Gillman, Barry Radler, Anita Rocha
This was the first GoToMeeting of the Methodology gropu, and was intended to establish a regular working group for the Methodology content in DDI. Steve Introduced the purpose of the meeting and set out the initial agenda:
Determine a chair
Set out a workplan
Look at the current state of the Methodology model (from sprint and Jay’s subsequent work)
Determine next steps
Michelle Edwards (CISER) agreed to take on the chairing of the Methodology group. Steve chaired the first meeting with Michelle to take over in future.
Steve began with a discussion of the outputs of the Minneapolis sprint, in particular the discussions with the MPC group. Steve then presented the work done by Steve, Anita and Michelle on mapping out the existing DDI-C against the current DDI4 output (see attached images - 1, 2, 3). Wendy noted that the current content of DDI3.2 also largely imported the DDI-C content, and that it did need significant revision and modernisation, and potential deprecation of some content to bring it up to current practice. It was discussed that this breakdown might form part of the initial group workplan. Wendy also noted that we have three broad areas for each type of method that we may want to model:
{kind=link}
{kind=link}
{kind=link}
Design
- Implementation
Data capture process
- Post capture processing
- Analysis
Wendy also suggested that Analysis might want to be introduced into this methods breakdown.
Jay Greenfield then presented the work he had done on introducing the model into Drupal (http://lion.ddialliance.org/package/methodology). In doing so, he also introduced some new objects (including Method, Goal, BusinessFunction and Precondition) to enable consistency with BPEL/BPMN, and discussed the capacity for use of two swimlanes (in BPMN terms) for managing workflows in one and managing data in the other. There was general agreement that this approach would be suitable, and could potentially enable both machine-driven processing, and historial process description.
There was some final discussion about the Usage/Unit/Variable/Guidance section of the "ubermodel". The basis of this model originated with the Weighting work coming from the SDI team that is for discussion in DDI3.3. (Dan, Steve, Wendy and Anita all contributed to this team). Jay raised concerns that there may be some challenges with implementing usages that he would like to explore further. He also noted that there are some strong parallels with the DatumStructure developed by the DataDescription group that may be able to be leveraged in this Usage modelling. The group agreed that this would be the starting point for the next meeting.
To conclude, the group agreed to convene on a bi-weekly basis. Michelle as new chair will organise a regular meeting time for the group, and convene the next meeting at a time to be determined.
Steve gave an overview of what has developed with the Methodology Model.
In turn Barry described what has being going on with Instrument.
ConceptualInstrument is a design of some kind of data capture, which then is very similar to Design in the Methodology Model.
There may be a lot of interplay between Data Capture and the Methodology Model.
One possibility is that measurement turns into something more abstract, so "question" is a type of measurement, etc.
INTERPLAY between these models:
ConceptualInstrument = Design
ImplementedInstrument = Process
Rationale isn't in Data Capture, but that's fine because it's about why you're using the instrument that's been designed.
2 things for Monday:
- Working groups
- Use cases
Fundamentally DataCapture and the Methodology Model are very similar.
Should the Process box be broken down?
Jay proposed changing the name to "Process Step" that could loop back on itself and could have multiple Process Steps. A Process Step would lead to a Sequence and then more Process Steps.
Some users may want that. But would everyone? Would it seem like that they would be required to fill it all out?
Could "Process Step" somehow be optional? Is it up to the user to expand the "Process" down to whatever level they want?
This may be more of a documentation and marketing issue. We should perhaps put it out giving an example of the higher level "Process" example, and then also give example and option of the analytical level of "Process Steps".
Can we break out the "Design" and "Process" boxes if we need to and not if we don't need to?
If we want to break out Design, we'd really have to give guidance on how to build a model. But Designs are so method-specific.
We could put an extension point from Design, and then people could create the specific Design for whatever Methodology and then attach it.
The key is that we need an exit point at the level needed by the user.
"Process" may have a repeatable "Process Step" attached to it that allows users to go to the level of detail they desire (see the model in Drupal).
Action Item:
- Jay is going to upload the current model to Drupal.
- Walk this through with Instrument.
Conclusion:
- Process is easy to write out; Design is hard. (Dan)
Where are we? And what do we need to get done?
What are the plans for the Harmonization and Confidentialization?
- Walk through the process (e.g. Harmonization)
- Identify the broad stages involved in the process
- From these stages, identify the Design (and it’s rationale), Procedures and Outcomes
We want to look at the Design, Process, and Rationale of these methods.
At the beginning of MPC they took a sample of the 1880 census and then took another one and made the codes the same to simplify.
When MPC is harmonizing, it's not the same things. Also, they deal with different languages. Everything is made by people, so there can be errors and a lot of variation
There were principles of what Data Integration IPUMS was going to do, which may be part of design of how they harmonized information.
The process:
- Getting the data:
- IPUMSI often starts with the full set of data, and may have to anonimize and confidentiality and add the sample. Which all has to happen before things can be integrated.
- Public use files of surveys come clean because a government agency was tasked to clean it up before the MPC ever receives it.
The integration of this on the methodology side, is understanding that it's the output of one thing and then the input of the next thing. So we're interested in what the processes are to go from output to input.
- The Rules for Confidentiality
- Is this written down and how does someone figure out that these are the rules?
- Are there contingencies?
- Times have to be taken to stop and do the research (this may not be documented)
There are multiple version of integration. So the model would need to be able to fit those into the framework.
The set of activities: Input Material > Pre-processing > Standardization > Integration
Confidentiality feels more compact and concrete:
IPUMSI process:
- Input Material
- When the data is received from the partner countries, it has varying degrees of documentation and metadata
- Try to get data files, enumeration forms and instructions, some of the published tables, documentation of sample design and collection.
- Try to get several of the census samples all together before processing starts.
- (1)Base template:
- Sample Characteristics
- Collection information (manuals, reports, processing syntax, ...)
- "Base" Metadata
- Information without a home
- Envm. and Sampling (input to sample weight
- (Original input data. Codebook and syntax aren't always clean, so they have to clean it up.)
- (2)Export content from documents
- To machine-readable format
- Reconstruct syntax to read files
- Into Excel file
- there is a macro that can generate syntax files; also programs can read the Excel file
- (variables in IPUMSI were arranged by usage because processing time was expensive)
- (3)Reformat Data into E/W File
- To relevant file structure (e.g. household, person, ...)
- Some IPUMS specific management variables may be entered
- Offshoots where the records are not across all members of the sample
- (4)Donation: Documented in IPUMS-USA
- (5)Confidentiality A:
- Apply a set of procedures
- which procedures are applied depends on content of the sample? (if/then)
- Confidentialised samples are (rarely) then reviewed by the depositing country
There are versions and notes if there are major changes during between the annual version.
Do MPC provide weights? If depositor has drawn sample and weights, it goes through the system, if not MPC draws them. MPC provides them with the syntax to correct the weights.
- Code Clean-up
- Undocumented codes
- Verify data
- Need to align skip patterns with post-processing instructions
- Confidentiality B
- Recode geographies > aggregate
- Harmonize:
- Build (add to) excel file of harmonized categories
- Macro to input content to excel file
- Human input to align sample code with IPUMS code
- Document differences in definitions in the documentation
- Comparability is a process of human judgement
- Variables can differ on multiple attributes (e.g. reference period, questions, universe, code, ...)
- Develop a classification!!
- Start with ISO codes wherever possible; and UN standards and guidelines; but then creating as they go.
- For counts there are issues of degrees of detail. More detail as storage is cheaper.
- Build (add to) excel file of harmonized categories
- Code Clean-up
(Images of board so far: Image 1, Image 2, Image 3)
- Variable Programming
- Common computed measures(e.g. household position)
- Constructed variables
- Creation of (for example) summary variables (e.g. insurance, receiving, vitamin a, ...)
- "Missing" variables (e.g. have total and female so complete male)
- Question: How do you write documentation?
- Variable Programming
- In the US there's a data quality flag that tells what we did (or the census bureau)
- "Data Quality" can mean so many things, so can it be boiled down enough for a flag?
Is this intentional design or accumulated process? There are some design principles.
GSBPM/GLBPM - Gives you all the process steps three levels down
How far down the rabbit hole do you go? That's the users choice. We have to decide how far down we support.
What tool do we capture the DDI process?Could it be done all in BPMN and then reference the relevant DDI.
The level of Process Steps may be where the DDI process is more useful.
There may be a worry that the complexity may be required by the users even though they could choose the level of complexity. Would that mean taking the Process Model out of DDI?
At the end of looking at all the information about Weighting in the morning, when describing the process it could be done at different levels for different audiences.
For some reasons (e.g. provenance) there's need to get into some pretty hairy details.
We need something that's either inside the standard or can talk to the standard.
What are we proposing the DDI Process Model for? Instrument, Prescriptive Process (proposed), Historical Process (proposed), Methodology.
If there are already lots of models out there, what are we providing here that's different? Something that natively understands DDI metadata. We don't want to duplicate and compete, but we do want to provide what are users need that's native inside the system.
The idea was to always interface with BPMN in the Process Model. There are issues when it comes to calculations, new language being developed, etc. There was a clearer sense of a region in which we would operate and a region in which BPMN would operate. There's a document from the Washington DDI conference that visit this.
How far down the rabbit hole? Not producing for new language, or calculations, but being able to incorporate down there along with having the inputs and outputs.
Let's address who will use this:
- Some people could go a long way with it.
- There would be a desire for the outcome of metadata driven processes.
- But there are people who will say "this is far enough"
We need to produce something that's not a mandatory part of the process. So we can go down a variety of levels.
There is a need for a Process Model; but should it be coded in DDI.
For Provenance and Preservation purposes, having the ability to put that stuff in, so that down the road when it's archived it's in a way that DDI will understand.
The Methodology model wouldn't say how to do coding, weighting, etc., but says what parts are needed for those things.
We're trying to develop a robust and inclusive Methodology Model that will show the basic necessary objects, and then give extensions points for people to drill down into the details of their methods.
Could we explode the Design Box in the model? If no, then that's an extension point for people creating specific methodologies.
Conclusions:
- There's a place beyond which it's unreasonable to go.
- At that point we should stop and provide an extension point to allow people to go further.
Can we describe how we do that extension point?
Images from later afternoon:
{kind=link}
{kind=link}
{kind=link}
The work that we're looking at at the moment is how far we can go with this rationale model.
Yesterday we applied this model to weighting. We tried to apply this to sampling. The recognition was that "x" is an outcome. For sampling it's a selection since sampling is the design and process part of the model.
"Variable" - is it necessary? Or should it have a different cardinality of 0..*?
Is this single-stage or multi-stage? It does account for the multi-stage and it's executed more at the "design" part.
The description is the overall process is in the Design, but the execution is in the Process by a set of process steps.
The Sampling Model would be a description of the Design.
The questions for today and tomorrow are to break out the Design and Process boxes.
Could you do something similar to fit in the Methodological Model for Coding and Weighting? Concentrating on the Design box.
Can we standardize the Design box for feeding into the Process box?
There may be overlap with Instrument.
Looking at Arofan and Jay's document from Dagstuhl. Here we're saying what we're going to in a method for a Process.
This may be useful to look at in the InputType, InputInstance, Citation, OutputInstance, etc.
This is very similar to GSIM (in the central column). We should really look at GSIM.
One takeaway is that you can describe a method at any level of granularity.
You could have a process step design that says you're doing a multi-step thing, and then the process model wouldn't go down and describe each stage specifically but the entire process of stages.
In the document there's an early example that looks like a higher level example of Process that each box could be a Process Step and is similar to GLPPM.
Let's take a quick look at GSIM and Instrument and see if we're getting similar things - as Barry is seeing a lot of overlap in Instrument.
Looking at the GSIM Process
- We didn't include Process Control Design but we need to in some area of the Process.
- Each Step can have a specification, and so we get into the distinction of human and machine readable and that's where we can get into the distinction of the boxes in this model.
- The key pieces to this Model is in the ProcessInput/Output and Process Step Instance. These may be in the Instrument work as well.
- We may not need to worry much about the conceptual and implemented parts now.
Can we describe methodologies in terms of design in this way or not? Can we describe weighting and coding in a basic input and output approach?
Barry has already used Instrument to create what is a Methodological Design.
- A questionnaire design has set a of Process Steps and captures the idea of what we're looking for.
Let's map out a Coding and Weighting Process.
CODING:
Develop "index" mapping phrases to codes
Develop Rules for disambiguation (where would a body of knowledge go in DDI4)
Rules for difficult cases
Identify people roles:
- Vocabulary development
- Training
- Supervision
- Coders
Manual process inform machine learning process
Automated system first then manual
Update of machine learning database
QA on sample of coded data
Identification of training needs
Conclusion: This can be done at a high level, but a real question is whether someone would want to; this is quite difficult.
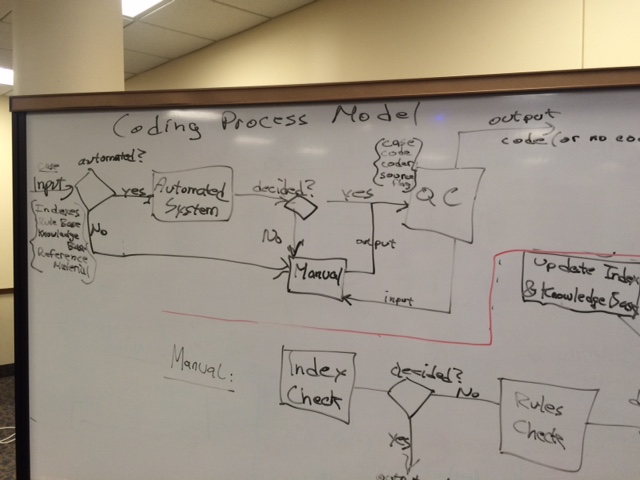
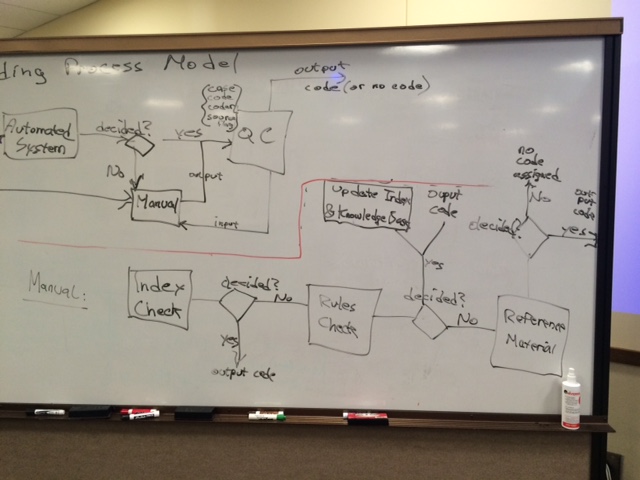
Narrative description of a Coding Process Model
Pre-Inputs
- Classification
- Indexes
- Rule Base
- Reference files – more detailed information for hard to code cases
- Knowledge base - drives automated system
Input a case (input = piece of text)
Check for automated system
- Yes send to automated system
- No send to manual system
Automated system
- Automated system decides case –
- Send to QC system
else - Send to manual system
Manual system input indexes
- Split – multiple coders/assign case to coder
- Each coder – index check
- If Decided? Send to QC
- Else rules check
Rules check
- If decided yes send to QC and index update
- Else reference material
Reference Material
- If Decided yes (send to qc and index update and knowledge base update)
- Else no code assigned
QC System (inputs: case, code assigned, source flag)
- Decides – evaluate or pass
{kind=link}
{kind=link}
Looking at some of the history and purpose of this group.
Reviewing the Methodology Model to look at how it operates.
We have our example case, can we fit it and other methodology approaches into this framework? This is where we could work from.
One of the parts is separating process from the output - which is "x".
Sampling Plan Model explained by Dan [see Sampling slide deck].
What's the purpose of have strata outside of frame, but a cluster would be in the frame? It's useful to have the strata outside to tell what it is.
One thing that's not here is a full description of a systematic sample.
How can the Sample Model fit into the Methodology Model?
- It comes down to defining "x"
- The Sample Model describes the Design
- Would "x" be the Sampling Unit? But there are strata, cluster, etc. would need to be attached to it.
- Depending on what's "x", a Sample could fit into the Methodology Model.
What if "x" is Selection?
- May have to redefine Variable and Unit
- Could Unit be the survey?
- Would this require Variable to be optional?
- Variably could be a Strata
- Dan's provided the Design and Rationale in his slide deck.
Harmonization would be a nice check of this model.
We need to give direction to other teams to see if we can fit such things into the model.
If we sat down with someone (e.g. harmonization?), what would we ask them?
- What pieces of information do you use in harmonization?
- Is this information useful to our group?
- It would capture their language. And we'd be able to link it back to their information.
- The question to throw at people is "what are you applying your certain thing (e.g. harmonization, confidentialization, etc.) to?
- Is this information useful to our group?
Where we got to:
- Things may be moving over to Design, Process more than we may have expected.
- This pattern is producing some kind of application ("x")
What does the process look like?
How much detail we want in Process may be open for discussion. GSIM did produce a Process model that we could incorporate.
We have a Process model that at this level becomes Process Steps.
There are two processes. The process of creating and the process of implementing - we want the process of implementing the design.
There is the Process Model on Drupal - Jay gave a brief description.
Steve's question - Can we describe in our design and rational the appropriate inputs?
Is this a generic enough model to implement? Can we describe the process? More work definitely needs to be done to execute it.
There are decisions about design and process that are outside the actual description of what you're doing... why?
We're going to look at Harmonization and Confidentialization on Thursday.
Notes from the discussion clarifying the intent and coverage of this group